
UPDATED: Google has since announced they no longer use Chrome 41 for web rendering. They now rely on the most recent version of Chromium (Chromium 74 at the time of this writing).
What does all of this mean? Is Google perfect at rendering JavaScript?
You can find the answer in my more recent article “Is Google Ready to Catch Up with JavaScript?“
If you are interested in the subject of JavaScript, I strongly recommend reading my “Ultimate Guide to JavaScript SEO.”
And if your website struggles with rendering, don’t hesitate to contact our technical SEO experts and ask them any questions!
Google updated their Search Guides and announced that they use Chrome 41 for rendering.
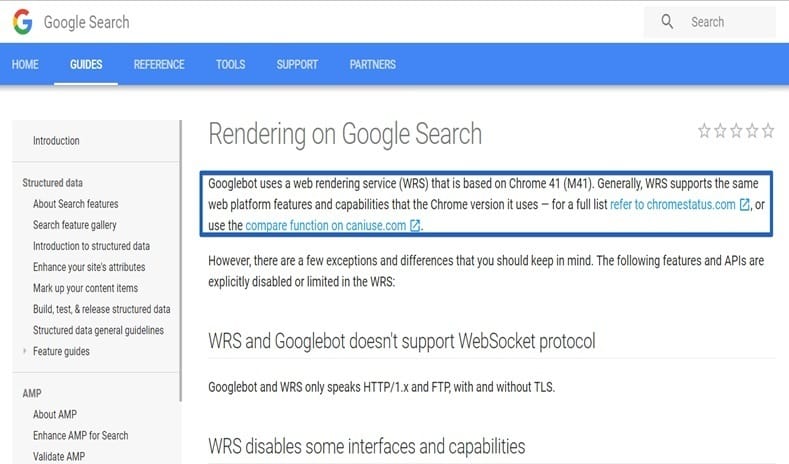
This was great news. Our CEO, Bartosz Góralewicz, even published an in-depth article about it at Moz.com: Google Shares Details About the Technology Behind Googlebot.
Before the announcement, we could only guess if a page was rendered correctly by Googlebot. Now we can simply download Chrome 41 and see how the websites behave in this browser.
In most cases, if it works in Chrome 41, this means Googlebot (or, more precisely, Google’s Web Rendering Service) interprets the website correctly.
In this article, I will show you
- what features Googlebot supports.
- how to use Chrome 41 to check if Google can see menu links.
- how to troubleshoot JavaScript rendering errors.
- what the differences are between Google Indexer and the Google Search Console Fetch and Render tool.
Googlebot’s features
The “Rendering on Google Search” guide provides us with many interesting insights into Googlebot’s features.
According to the document, there are some limitations related to content storage. For instance, HTTP cookies, localStorage, and sessionStorage are cleared across page loads, while interfaces like IndexedDB and WebSQL are disabled. And most importantly, it doesn’t fully support the new JavaScript syntax – ES6 (officially called ES2015).
Google’s official statements were not enough for us, so we went deeper and set up a feature detection test at Crawlrecon.com. To accomplish this, we used the feature-detection library, Modernizr.
This gave us some information on the differences between regular browsers and Googlebot, which we have listed in the following spreadsheet.
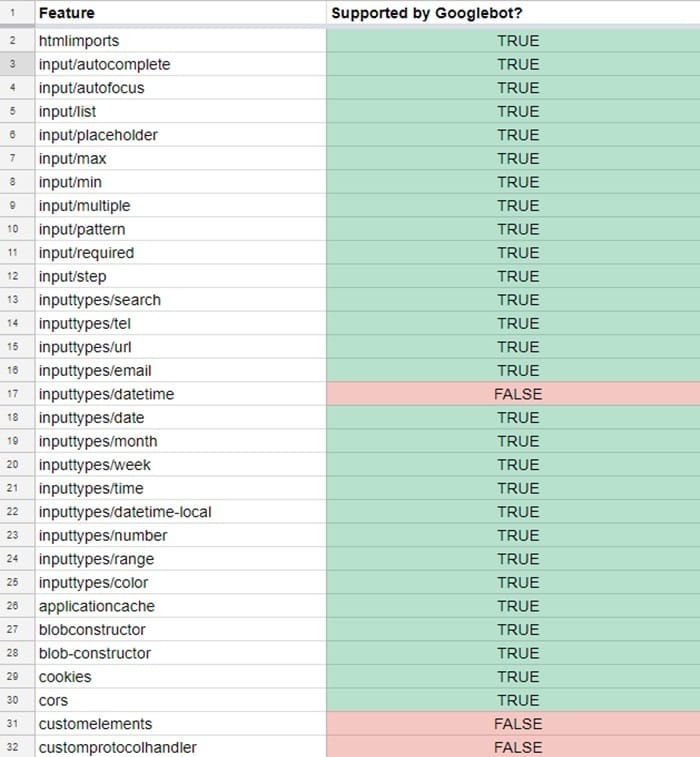
The document also answers your questions regarding:
- Googlebot vs. Chrome 41 features.
- Googlebot vs. Chrome 6x features.
While the spreadsheet doesn’t provide a full technology break-down, it can help you and your developers make your website crawlable and indexable.
Also, I recommend checking what functions Googlebot (Chrome 41) can use by opening CanIUSe.com. Here, you can even see what the differences are between Chrome 41 and Chrome 6x regarding supported features.
Google Fetch and Render is not a silver bullet
One might say, “If a website works for Google Fetch and Render, it will certainly work in the Google search engine.” However, there are some limitations we have to be aware of.
Fetch and Render is more limited
In a JavaScript SEO forum, Googler John Mueller said, “FWIW the Fetch & Render tool is a slight bit more critical than what we use for indexing. If it fails there, we might still be able to get something from the page for indexing. However, if it works there, then we certainly can use it for indexing. This is particularly the case with latency & caching of embedded content, where a one-off testing tool optimizes for fresh content (or fails if it can’t get it quickly enough), and the indexing system optimizes for cached content & is fine with slower responses (to avoid stressing the server unnecessarily).”
According to John, Google Fetch and Render is optimized for performance, while the indexing system (Caffeine) is slightly more tolerant with slower responses.
It’s worth noting that John’s statement definitely can’t be interpreted as an encouragement to skip activities related to improving a website’s performance. Does anybody want to wait half a year for Google to crawl all the pages in the structure, making only 100 requests per day?
The fact is that the slower the website is, the fewer requests Google can and wants to make.
Google Fetch and Render doesn’t always report timeouts.
I performed some experiments at https://hireukrainiandevelopers.com/hire-javascript-developer/ related to Googlebot’s timeouts. What I’ve noticed is that when Fetch and Render executes an internal script and encounters a timeout, it doesn’t always report the timeouts that occurred.
What is very interesting and a bit frustrating, in some of the Botbenchmarking.com tests, Google stopped executing crucial scripts (they were responsible for injecting content) and indexed just boilerplate content, such as “Some random text will be injected.”
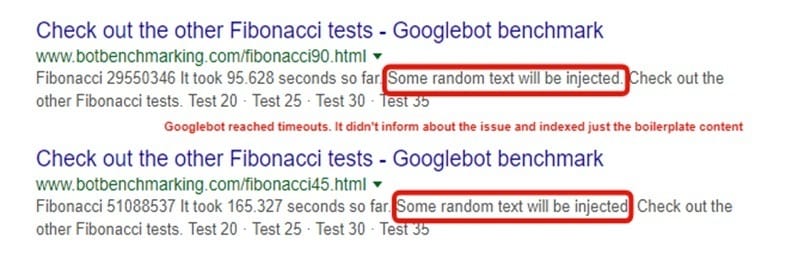
The question arises: does Google classify these scripts as redundant from a rendering point of view? Or is this the general rule:
Google encounters a timeout while executing a script -> Google indexes a page as it is?
This topic needs further investigation. I really would be glad to know your feedback.
Chrome 41, which you can install on your computer, will keep executing a script, even if it takes ages. However, it’s wise to assume Googlebot doesn’t wait longer than 5s to execute a script.
[A side note: The snippet “It took 95.628 seconds so far” doesn’t indicate that Google has been executing the script for 95 seconds till the timeout exceeded.
I performed a simple script that measures how long it took for Googlebot to finish code execution. For some reason, this benchmark worked only while measuring regular browsers, like Chrome 66 and Firefox. But when Googlebot executed the script, the time measurement failed and returned improper values.
If you found an error in my script, please let me know. I was writing the code on my own, although I’m just an SEO, not a JavaScript expert :)]
A lot of websites around the web use “Vh” CSS units. However, we’ve noticed some issues related to this: Google Fetch and Render can’t show content outside a
that is styled using the “100vh” attribute of CSS.
We conducted an experiment to see if it could be a problem: https://hireukrainiandevelopers.com/hire-javascript-developer/
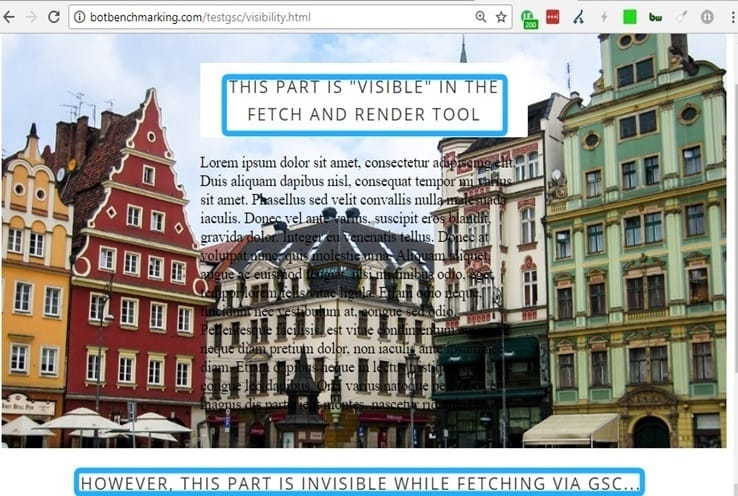
The result? Fetch and render was able to see just the main <div>. Other parts of the website are omitted by F&R. This screencast illustrates the problem:
The problem can be even deeper. It can refer to all websites that always scale the content to a viewport.
To see what I mean, you can open https://hireukrainiandevelopers.com/hire-javascript-developer/ in your browser. Then press “CTRL minus” a few times. I bet you still can see just the main div. Once you scroll down, you can see the rest of the content. But the Google Fetch and Render tool can’t “see” the content.
As far as we know, it doesn’t affect indexing.
But then the question is: does this issue affect ranking? Or affects only the way Fetch and Render sees your content? For the time being, I don’t know the exact answer. Did you encounter similar issues related to Fetch and Render? I would be happy to know your feedback.
John Mueller gave us some interesting hints on how to check if Googlebot can see drop-down menus in a JavaScript SEO Group.
The takeaway is clear: If your menu is inside the Document Object Model (DOM) before clicking any menu item, it should be picked up by Googlebot. Otherwise, it’s very likely it won’t be picked up at all.

To check this in Chrome 41, just click on the “Inspect element” button. And then search for any menu-specific fragment.
[Side note: technically, you can use any browser for the DOM inspection. But, do you have any arguments for not using the browser used by Google’s Web Rendering Service? Since we all know Google uses Chrome 41 for rendering, let’s take advantage of using this browser to make your websites crawlable and indexable :)]
To illustrate what I mean, let’s use an Ebay.com example:
At Ebay.com, there is a drop-down menu.
Let’s check if Google can see this and follow the menu links.
We can pick up Electronics -> Additional categories ->IPhone category.
- Click “inspect element” (or Ctrl Shift I).
- Go to the “Elements” tab.
- Press Ctrl + F and search for “iPhone.” Indeed, it’s in the DOM so that Google can see this!
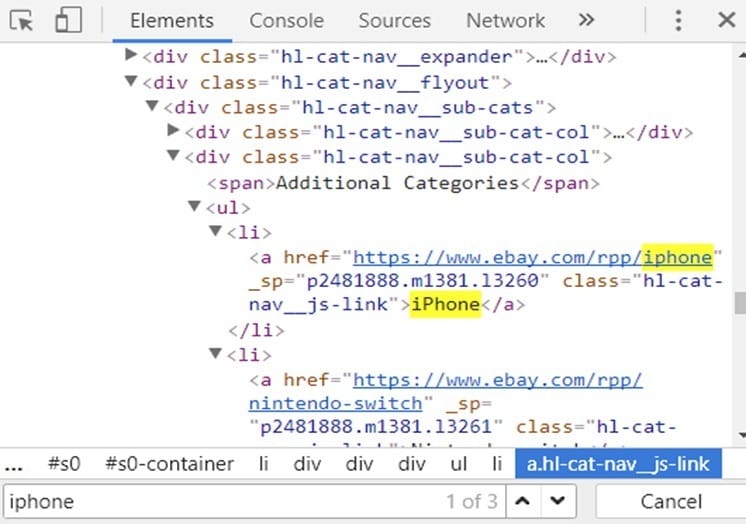
[Side note: if you are unsure about investigating the proper node, just edit the internal text “iPhone” and see if the menu was updated.]
Here is a screencast illustrating how you can accomplish this:
Our quick investigation showed that Google can interpret Ebay’s menu properly. However, this isn’t always the case. There are tons of websites with menus and content hidden under tabs Google can’t handle.
To avoid pitfalls, always check it using the Inspect tool in Chrome 41.
Using Chrome 41 to check the errors Googlebot gets
The following scenario is very common: Google Fetch and Render shows you that it can’t render a page correctly.
To investigate the source of the rendering issues, open Chrome 41, look at the console, and see what errors occurred.
To demonstrate the scenario, I created a simple page.
The page contains a very simple script that takes advantage of a very common “let” command (a part of the ES6 JavaScript syntax).
I was checking if Googlebot supports it by opening it in Google Search Console and in Chrome 41. To compare the results, I checked if the newest version of Chrome could render it correctly.
The script is very simple. If a browser supports ES6, it replaces a paragraph with the following text: “Yeah, your browser supports ES6”.
Chrome 61 renders this page perfectly:

What about Fetch and Render?
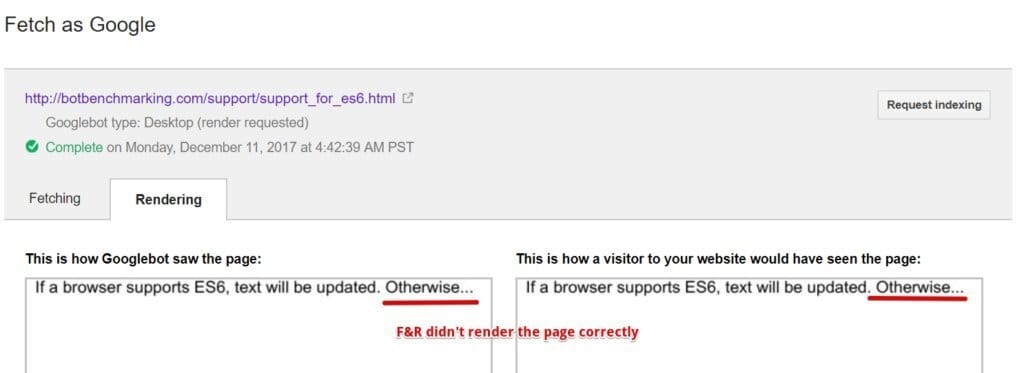
OK, so open this page in Chrome 41 and see what errors occurred:
I don’t want to go too deep with the programming stuff. If you are not familiar with console errors, the best option for you is probably sending the information about the errors to your developers or Googling it. For sure, they will know how to deal with errors like this.

So if I described you above, just go ahead and skip to the next section. However, if you know what I’m talking about, then please keep reading.
What does this error mean?
For those who really want to know what this error is really about, I’ve prepared a short explanation.
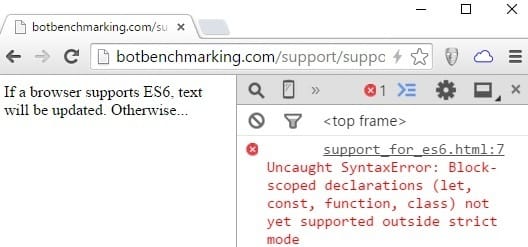
Chrome 41 throws a Syntax Error:
“Line 7; “Uncaught SyntaxError: Block-scoped declarations (let, const, function, class) not yet supported outside strict mode”
An error indicates it’s caused by the “let” declaration in the seventh line:
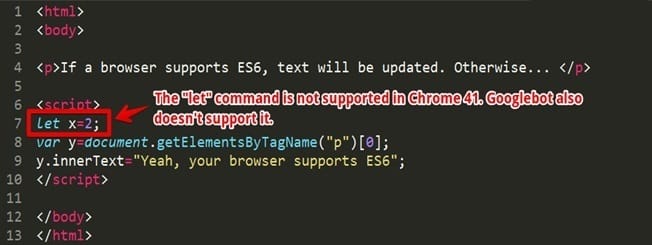
Ok, but what’s wrong with the “let” declaration?
Let’s check CanIUse.com:
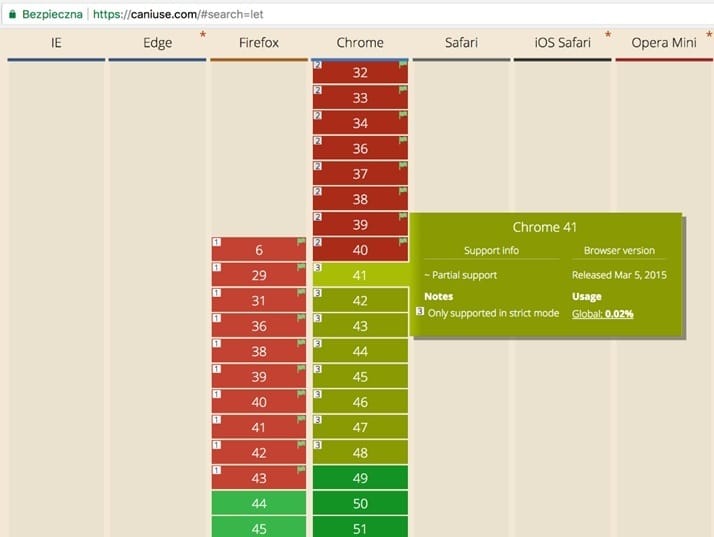
Bingo! As you can see, it’s not fully supported by browsers older than Chrome 49. CanIUse.com indicates Chrome can use it only in strict JavaScript mode.
How to make it work?
- You can use a strict mode in your JavaScript code.
- You can use tools like Babel that allow transpiling to ES5. In a transpiling process, the “let” declaration is replaced by the “var” declaration (which is fully supported by Googlebot).
Crawling budget – browsers are not like Googlebot
Google can properly render a large number of modern websites. However, the problem is more trivial. Googlebot doesn’t act like a real browser. What does a standard browser do? It downloads all the resources: JS, CSS files, images, movies, etc. and shows the rendered view to users.
Googlebot acts differently. It aims for crawling the entire internet, grabbing only valuable resources, and sending it to the indexer. The World Wide Web is huge. So Google should (and does) optimize its crawlers for performance. This is why Googlebot sometimes doesn’t visit all the pages webmasters want.
Google algorithms try to detect if a resource is necessary from a rendering point of view. If not, it probably won’t be fetched by Googlebot.
Also, another factor plays a role. Googlebot adjusts its crawling speed for website performance. If Google detects that the response time is very slow or the requests from Googlebot make a website noticeably slower, it can lower the crawling speed.
If a website contains many time-consuming scripts, Chrome 41 will execute this and render a page. Whereas Google Fetch and Render and indexer will probably stop executing a script after ~5s — referred to by many SEOs as the 5-second rule.
The future
There is strong pressure on Google to upgrade Googlebot’s features and make it up-to-date.
Google promises that its rendering machine will always be based on the newest version of Chrome in the future.
When we spoke with Ilya Grigorik from Google, he said, “Last thing we want is every developer running an outdated version of Chrome. Fingers crossed, we’ll have better solutions in 2018+ :)”
And more big news is coming. John Mueller claims that Google is working to make Google Search Console Fetch and Render show not only a rendered image, but also a rendered DOM snapshot. “We’re working on including a copy of the rendered HTML/DOM in a tool that should hopefully be out soon.” Once they finish it, troubleshooting will be much easier. One will be able to see exactly which elements Google was able to pick up.
Summary
The news that Google’s Web Rendering Service uses Chrome 41 gave us an enormous amount of insight on how Google sees websites. Using Chrome 41, we can discover (with high probability) if Google has problems fetching content. If there are any problems with rendering in Chrome, just look into the Chrome Developers Console for any errors that might have occurred.
We have to be aware that there is a slight difference between Chrome 41 and Googlebot (or to be more precise, Google’s Web Rendering Service) regarding supported features. Also, we have to keep in mind that Googlebot doesn’t act like a standard browser. Here, other factors, like crawling budget and the speed of a website, play a significant role. These factors can really affect crawling and indexing! An SEO shouldn’t forget that.
If you’re interested in knowing more about JavaScript-based websites and SEO, then you absolutely must read my Ultimate Guide to JavaScript SEO.








