
How Thousands of People Missed One Simple Mistake!
Earlier this year, I conducted an experiment on how Google crawls and indexes different JavaScript frameworks, including Google’s own JavaScript framework, Angular JS. The experiment was meant to do a lot of lofty things, such as open communication between JavaScript developers and SEO and hopefully save clients serious money when it came to website development.
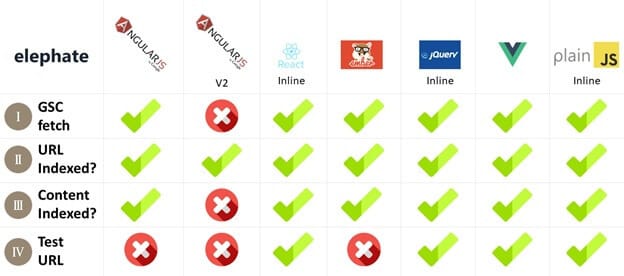
I wrote about the results of the experiment and it quickly went viral.
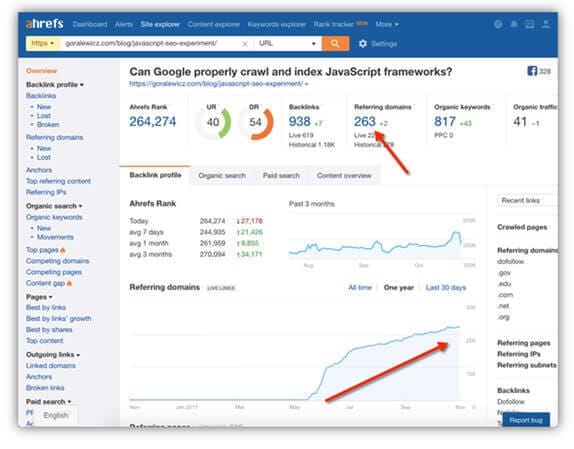
However, the most interesting part of my research on JavaScript happened after the article was published, because even though a lot of people read and talked about my experiment, no one seemed to notice one thing that was staring everybody in the face.
It was wrong.
Let’s examine how that might have happened.
ONE THING LEADS TO ANOTHER
The data I collected from the experiment created a kind of domino effect and unraveled a lot of new problems I was previously unaware of. This naturally made me intensify my research and I started asking even more questions. My additional experiments involved JavaScript vs. crawler budget, Single Page Apps crawling and indexing and more.
All of this brought me to one solid conclusion: JavaScript-generated links weren’t crawled when JavaScript was placed externally.
DIDN’T FEEL LIKE IT? WAIT, WHAT?
After seeing the results from my experiment, John Mueller, a Webmaster Trends Analyst at Google, started a forum on JavaScript SEO. I used this opportunity to ask John some key questions. I was concerned about how Googlebot wasn’t crawling JavaScript links, particularly if the JavaScript code was external or executed through AJAX calls. This issue was especially important because we always advise clients to externalize JavaScript scripts for performance purposes. And it was also bad for website architecture.
John was kind enough to peek “into [their] systems” and told us that Googlebot saw the links in question, but “didn’t feel like crawling [them].”
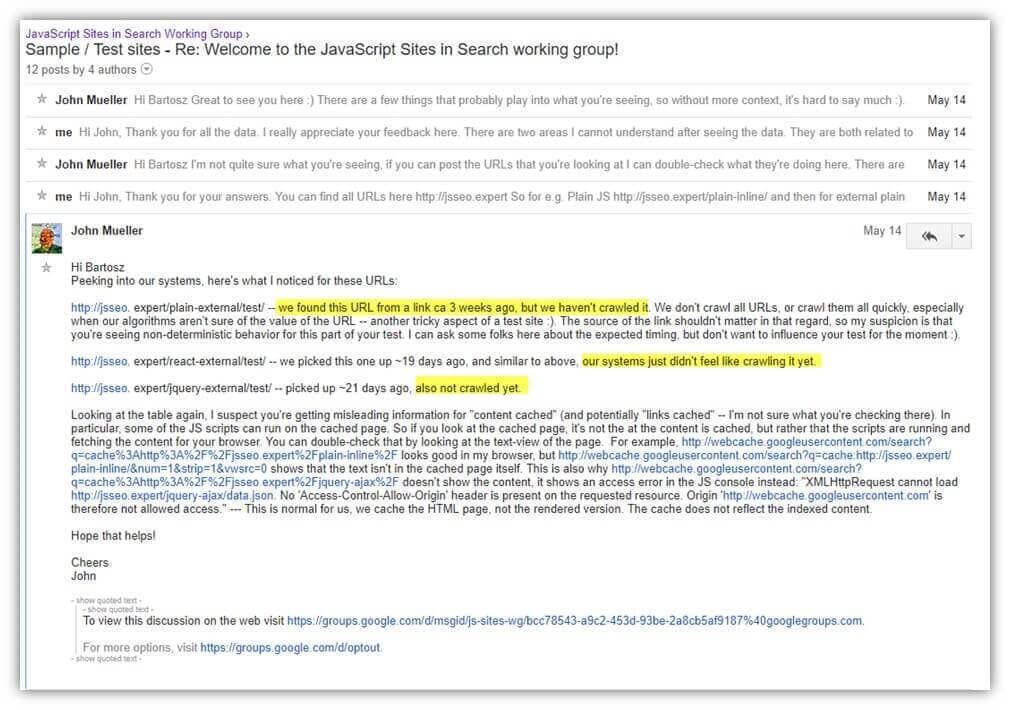
John was enormously helpful, but I had concerns about how abstract some of his answers were. It felt strange that he was describing Googlebot the same way a manager at McDonald’s might describe one of their high school employees:
“Brad just didn’t feel like cleaning the bathroom today.”
In other words, his answers weren’t technical enough to lead me toward a solution. I knew I was missing something.
A LIGHT IN THE DARKNESS
JavaScript frameworks indexing can be a fun topic to explore, but it doesn’t really guide us in any specific direction. And more importantly, it doesn’t always provide answers to key questions.
In a lot of ways, SEOs are like the blind people trying to describe an elephant, because to fully understand JavaScript crawling, we need to wrap our heads around WRS (Web Rendering Service), Googlebot’s features and limitations, the protocol used for crawling and much, much more. All the while knowing that this could all change at the drop of a hat.
Eventually, a little light in the darkness appeared in the form of a tweet from Ilya Grigorik, a Web Performance Engineer at Google:
Rendering on Google Search: https://t.co/bgacWwNyz8 – web rendering is based on Chrome 41; use feature detection, polyfills, and log errors! pic.twitter.com/pNptcvpjFo
— Ilya Grigorik (@igrigorik) 4 sierpnia 2017
Ilya wrote: “Rendering on Google Search . . . web rendering is based on Chrome 41; use feature detection, polyfills, and log errors!”
A GAME-CHANGER
Finding out that Googlebot uses a WRS based on Chrome 41 was a revelation.
For years, SEOs have been focusing on the crawler budget, but no one had figured out the simple basics regarding the technology used to crawl websites. Google Search Console could provide us with a preview of the rendered website, but could not provide us with a diagnosis of any issues that might occur.
Chrome 41, on the other hand, not only gave us a preview of the rendered website, but we could see and fix any indexing problems that might occur with JavaScript frameworks.
This was, without a doubt, a game-changer.
STEPPING BACK
At one point we were having difficulty cracking how to get Google to index Angular 2 and Polymer, so I reached out to Ilya.
And while we did figure it out (spoilers!), it wasn’t an easy process. It required a lot more research, and we also had to navigate through Ilya’s often-cryptic clues like

and

“JavaScript is not bad for SEO, if done right,” and “HTML is very forgiving, JS less so”? Sometimes it felt like trying to get a straight answer out of Yoda.
He did make sense when I gave it some thought. Crawling HTML is a lot easier as the code is “ready to go” with all the content in it, whereas JavaScript needs to be rendered first before it gives up its HTML. So yeah, in that way, HTML is certainly forgiving.
It also helped explain why Googlebot didn’t always “feel like” crawling JavaScript while seeming to always “feel like” crawling HTML.
Just in case you need a visual:

As unforgiving as JavaScript can be, it’s here to stay. In fact, back in August, John tweeted about this very thing:
The web has moved from plain HTML – as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) August 8, 2017
Which is another reason why Google’s problem with Angular 2 was so frustrating. JavaScript is “not going away” and yet Google seemed unable to index it.
And it turned out that there was an error in Angular 2’s QuickStart, a kind of tutorial for how to set up Angular 2-based projects, which was linked in the official documentation. All that research to discover that the Google Angular team had made a mistake.
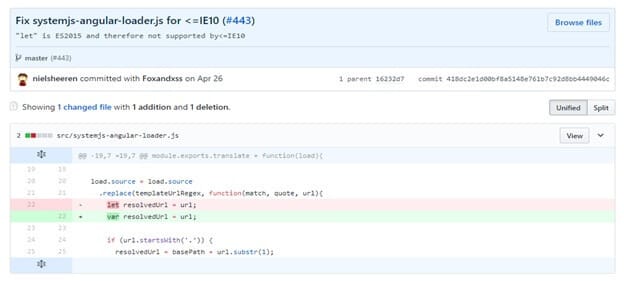
On April 26, 2017, that mistake was corrected.
And we all should have lived happily ever after, but I couldn’t help but wonder how thousands of people read and analyzed my original JavaScript SEO experiment, without seeing this problem. How could I have missed it? How could all of the technical SEOs and JavaScript developers I reached out to have missed it? And most importantly, how could the people I contacted at Google not know? John alone created a forum on JavaScript SEO because of this experiment and answered questions in hundreds of threads, and he still didn’t see any technical SEO problems.
This made me step back from the final results and look at the process of how we got there. What was different this time?
And then it hit me: there was no workflow to troubleshoot JavaScript indexing.
Up until now, to see if a page was properly indexed by Google worked, all you did was take a snippet of text from a page. For instance, we can use text from this JavaScript SEO experiment.
“In recent years, developers have been using JavaScript rich technology, believing Google can crawl and index JavaScript properly.”
We use the site command: site:{URL} {a text fragment}
And then we get this:
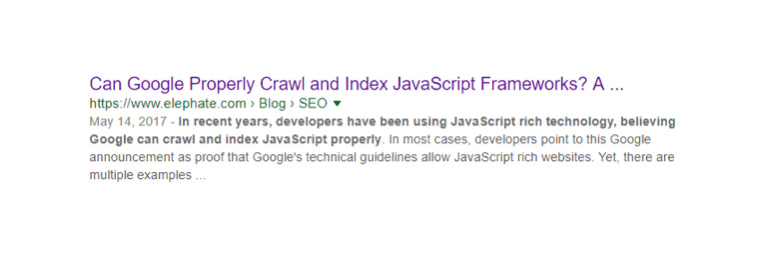
But that’s not always the case, and, more importantly, it doesn’t always give us a complete picture.
Reach out to us for Angular SEO services for better crawling, rendering, and indexing of your JavaScript content.Want to optimize your Angular usage?
HOW TO TROUBLESHOOT JAVASCRIPT INDEXING (WORKFLOW)

Download and open Chrome 41.

Go to any JavaScript client-rendered website.
Open Chrome Developer Tools.
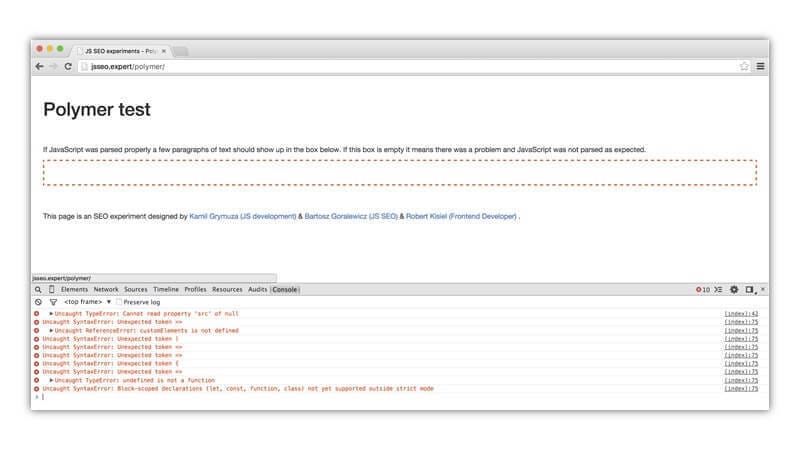
Access Chrome Developer Tools.
Click “Console” and look at all of the errors in red at the bottom.

And then share this information with your developers.
If you fix these errors, it’s a safe bet that not only will JavaScript be indexed by Chrome, but all browsers.
Need help with JavaScript SEO? Reach out to us to get the JavaScript SEO audit of your website.
IN CONCLUSION
What can we take away from all of this?
For one thing, it’s clear that Google is a complex organization, and it’s very likely that the left hand isn’t always aware of what the right hand is doing – hence the disconnect between smart Googlers like John and Ilya.
This disconnect can also work as a microcosm of how thousands of readers could miss the mistake in my experiment. SEOs can often get so overwhelmed with their own work – which often produces conflicting data – that they mistake the forest for the trees.
Since JavaScript isn’t going away, this workflow for troubleshooting JavaScript indexing will give us a better handle on our ability to see these problems early on so we can get ahead of describing that so-called elephant.
I hope this information was as valuable to you as it was for me. It certainly has opened up new possibilities for my continuing experiments and research.







