The Internet changes at the speed of light. There are nearly two billion websites today, and new ones are emerging every minute. You can even watch the number grow on Internet Live Stats. New websites are born while others disappear, and those willing to survive have to adapt.
In less than three decades, the Global Network has moved from a pixel-based, 8-bit stone age to the beautiful, high-resolution, responsive designs we have today. Do you remember how websites looked in the early days of the Internet? If you wish to refresh your memory, you can take a journey through the 99 entry pages preserved in time by Internet Archeology.

Rediscovering the past in the World Wide Web
Working as an SEO specialist, sometimes you might want to take a look at the past. For example, imagine you’re investigating a recent drop in a website’s visibility. You know there were some recent changes in the website’s code, but couldn’t get any details. Or maybe you’re preparing a case study of your recent successful project, but the website has changed so much, and you never bothered to take a screenshot. Wouldn’t it be great to travel back in time and uncover the long-forgotten versions of the website – like an archaeologist, discovering secrets from the past but working in the digital world?

Nothing gets lost on the Internet. In the digital world, information gets shared, copied, and embedded. It becomes a meme, a part of our cultural heritage, passed on from one individual to another. That said, do you really believe that once a website ends, the only thing left behind is a set of broken links? And is it even possible to recreate the content if all the resources were deleted from the origin server? Well, it wouldn’t be unless someone else saved it. And you might have a decent chance that someone actually did. But the question is: who?
Google cache is not enough
The first answer that comes to mind is: Google did. Whenever the Google crawler visits your website, it also creates a snapshot of the page. This gets preserved in the Google cache. You can access it by typing cache: before the page’s URL in the Google search engine. There you can see the page, check the text version, and even dive into the HTML code. Some SEOs did use this feature to check how Google rendered the given page. But this practice is obsolete, and we already know that it doesn’t work. So instead of checking the cache, you should be using Chrome 41.
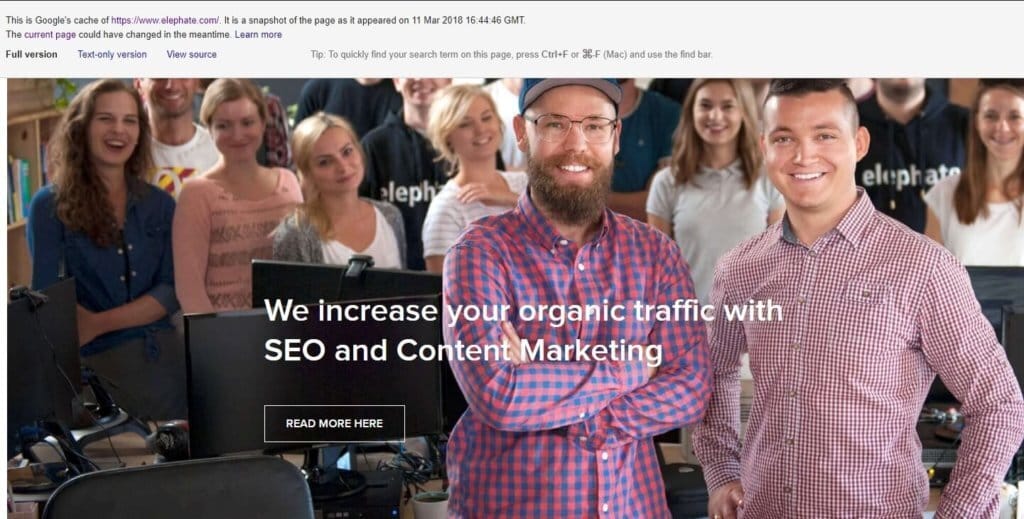
Is Google cache useful in any way, then? Well, the sole date of the cache will give you an idea when was the last time Googlebot visited the page. Ideally, it shouldn’t be older than a day. But, if you discover that the cached version of your page is three weeks old, this should ring a bell. Your website might have some serious issues concerning crawling strategy.
However, Google cache doesn’t enable us to dig deep enough. It only gives us access to the latest version of the page, which in 99% of the cases, would be exactly the same page that is working live. In terms of Internet Archeology, Google cache performs the role of a trowel. It lets us uncover the surface, but it doesn’t enable us to go deeper. Therefore, for our online excavations, we need a proper tool. We need a spade.
Travel back in time using Internet Archive
According to this report, around 50% of the overall online traffic is caused by bots, not actual humans. There is a variety of different automated programs crawling the web. Some of them are malicious such as scrapers, spammers, or hacker tools, other (search engine bots, feed fetchers, etc.) perform a spectrum of useful tasks.
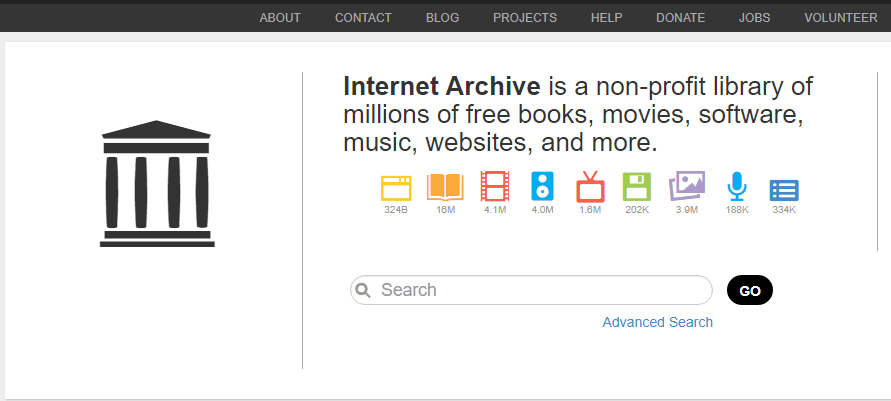
One such crawler has a rather unusual mission of perpetuating fragments of the digital world. It belongs to the Internet Archive, a non-profit organization that has undertaken the task of preserving digital information for future generations. They collect all sorts of data: book scans, videos (including television news programs), audio records, images, and even software programs. And, what’s more important for us, the Internet Archive gives us access to over 20 years of web history, with over 324 billion stored web pages! You can find them by using the Wayback Machine.
How does it work?
The service was set up in 1996 and went public in 2001, after five years of collecting data. In 2016, a more advanced version of the website was released. As mentioned before, the Wayback Machine uses a bot to archive pages. It navigates between websites by using a network of links. And it saves everything it finds in the process. The more links pointing to your site from other domains, the bigger the chance that your website will be discovered. Therefore, big and popular websites have a better chance of being stored, and a tiny personal blog might not be archived at any point at all. If you want to make sure that your website will be discovered, you can always use a save page button and send a URL that should be archived.

Online excavations utilizing the Wayback Machine
If you wish to discover the archived versions of a page, you should enter the URL in the search bar on the Wayback Machine (if you don’t know the exact address, you can try searching for it by the keywords it should contain). This is what you will get after typing your URL:
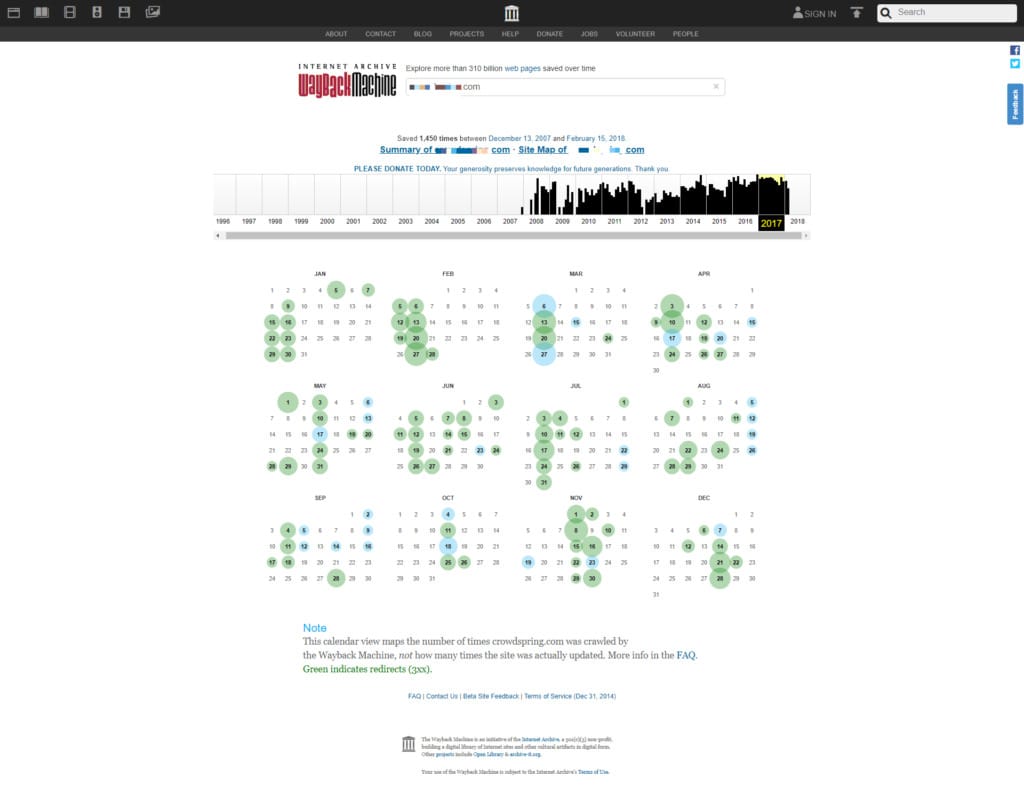
On the timeline at the upper part of the page, you can see a graph representing how many snapshots of a given page were created during a single year. After selecting a year, a number of dots, different in size and color, appear on a calendar below the timeline. The dot means that the page has been archived in a given timestamp, and the size of the dot indicates how many snapshots have been taken. One timestamp can have one, a few or no snapshots at all, and you can see the exact number by simply navigating to the dot:

As you can see, on November 16, 2017, five snapshots were taken of a given page at different hours. The timezone is GMT.
The dots can have four different colors:
- The Blue dot indicates that an object (URL address) has been successfully visited and archived;
- The Green dot reveals that an object contains a redirect to a different snapshot (or to a different object which might not be available in the archive);
- The Orange dot means that when a bot visited an URL, it returned the HTTP status code 4XX;
- The Red dot is an indicator that a server error appeared when a bot tried to reach an origin URL.
And the only dots that contain stored archives are the blues. The other colors might give you information about any encountered issues or changes in the website’s structure.
If you enter the given archive, you will get a version of the page encountered by the bot in the given time, and by using the timeline, you can navigate among the newer and older snapshots. What you will get might be fairly close to the original page, however, it won’t be a 1:1 copy. It will render the CSS and HTML of the original page, but it lacks the ability to handle JavaScript. In other words, if the page is dynamic and based on JS without rendering a static HTML, you won’t get an accurate copy. Also, the archive often has a problem with storing images.
Despite its limitations, the tool is still incredibly useful. It gives you the unique ability to investigate the history of a single page and its evolution over the years (provided that enough of the archived data exists).
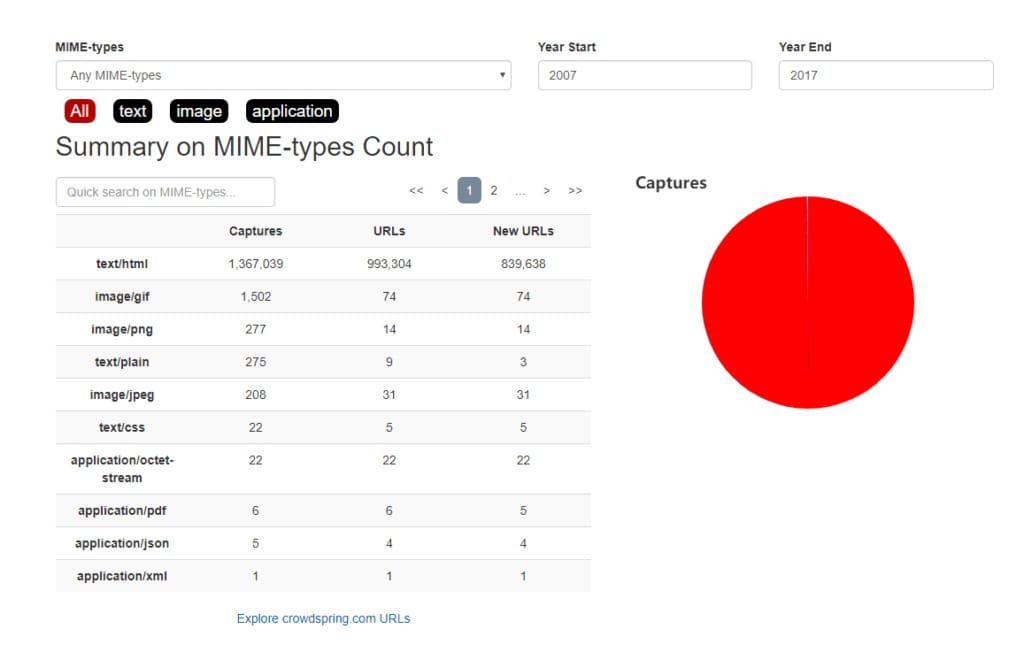
You can also access the summary of the page’s history. Here you can see the details concerning the resources of the archived page.
Using the Wayback Machine for SEO
After this introduction, we should have a fair idea about how the Wayback Machine works. But the question remains: how can we utilize its features for SEO?
Investigating changes in the website’s structure
If the website has been running for years, there is a fair chance its structure has been rebuilt many times. The Wayback Machine gives you the ability to see how the URLs have changed, and what’s even more important, it will provide you with insight into which pages have and haven’t been redirected. It is possible that somewhere in the website’s structure, long-forgotten pages are hidden. Combining the Wayback Machine and Screaming Frog can help you track down valuable redirect opportunities.
The sitemap feature might prove useful while investigating the old Information Architecture.
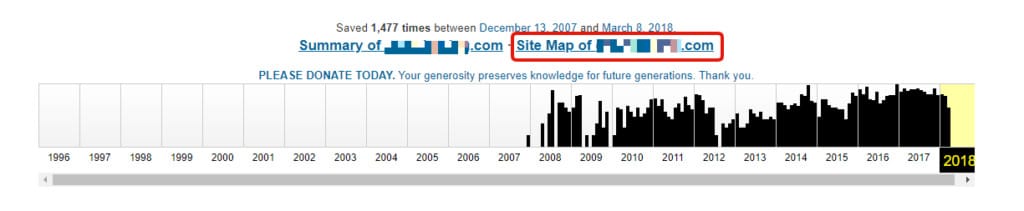
This will gather a year’s worth of data of the page’s archive to build up a scheme of the website’s Information Architecture. It is presented on a graph, with the inner circle representing the homepage. Subsequent subpages are added in the form of additional layers, just as you can see in the screenshot:
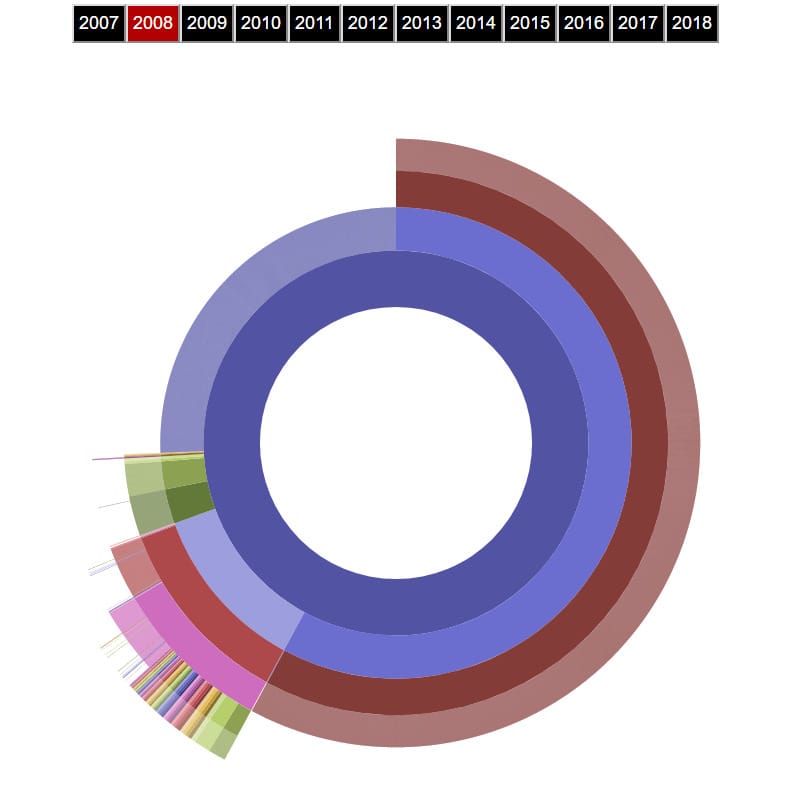
By clicking on different years, you can observe how the website’s architecture evolved over time. However, you have to keep in mind that this sitemap is not 100% accurate (actually, it might be rather far away from 100%), and its appearance depends solely on the Wayback Machine’s archive. If the snapshot of a given page wasn’t ever taken, the page wouldn’t make its way to the sitemap.
Retrieving the HTML code of an archived page
In the Wayback Machine, you can take a look at the HTML of the stored version of the page. This will allow you to investigate the metadata of the old pages, see the changes made in the code, or even check the analytics code placement.
You have to keep in mind, though, that the code has been slightly modified from its original form:
- All URLs (internal links, resources, etc.) have been modified, so they point to the archive;
- A big block of additional code has been added to create the Wayback Machine’s toolbar.
You may browse through the code keeping that in mind; however, there is a simple trick for extracting the original HTML. To achieve that, simply add id_ after a timestamp in the URL of the given archive.
For example, if the URL of the archived page is:
https://web.archive.org/web/20180306144012/https://www.elephate.com/
Then, the path to view the cleaned version of the code would be:
view-source:https://web.archive.org/web/20180306144012id_/https://www.elephate.com/
Investigating crawling issues
If your website’s GSC is reporting issues concerning the robots.txt file, the Wayback Machine can give you access to the old version of the file. First, you have to investigate the time range for when the errors started to appear and then look for the snapshots from this time range inside the archive. The archive stores everything it finds, so there is a decent chance that robots.txt also made its way to the database. You might be surprised how often it happens in the case of big websites:
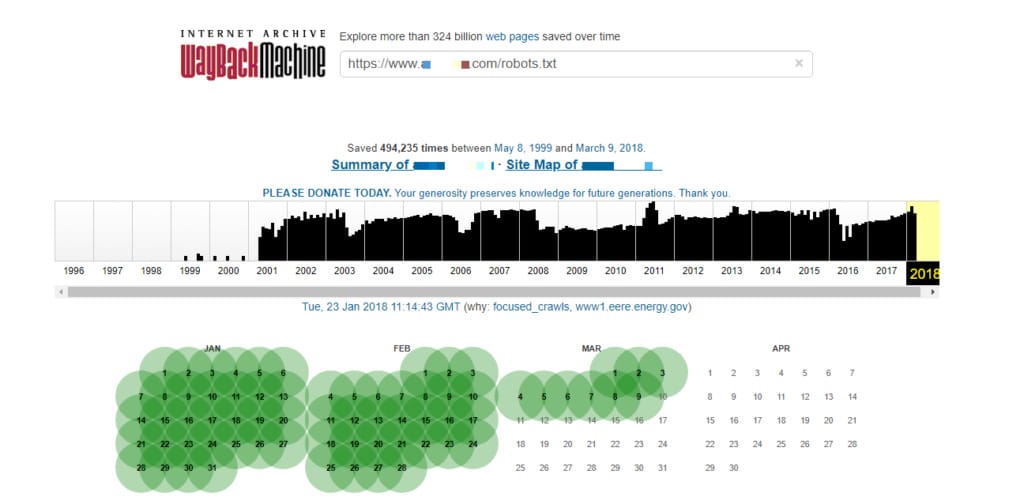
Recovering lost content
Last but not least, the Wayback Machine can help you recover what once was lost. If, for some reason, the content of a given page has been deleted and you don’t have a saved copy of that page, Internet Archive might save your day. You can hope that at some point, the lost page was stored in the archive, and if so, just retrieve the content. It’s as simple as that.
Here at Onely, we creatively look at SEO issues. If you want to try out new, custom solutions for your website, check out our technical SEO services.
Summary
Just to wrap things up, Internet Archive: Wayback Machine is a unique database of stored websites, though you have to be aware of its limitations. The archive has problems handling websites that rely heavily on JavaScript, and because it discovers pages by incoming links, it works really well only for big websites that have a decent amount of online visibility.
Keeping that in mind, the tool can really prove useful while performing a number of SEO tasks, and it gives you the unique ability to take a look at the past on the World Wide Web.