
Have you ever wondered how Google sees your website? In this article, I’ll show you how to visualize the underlying connections between your webpage. You will be able to achieve results like this:

And this:
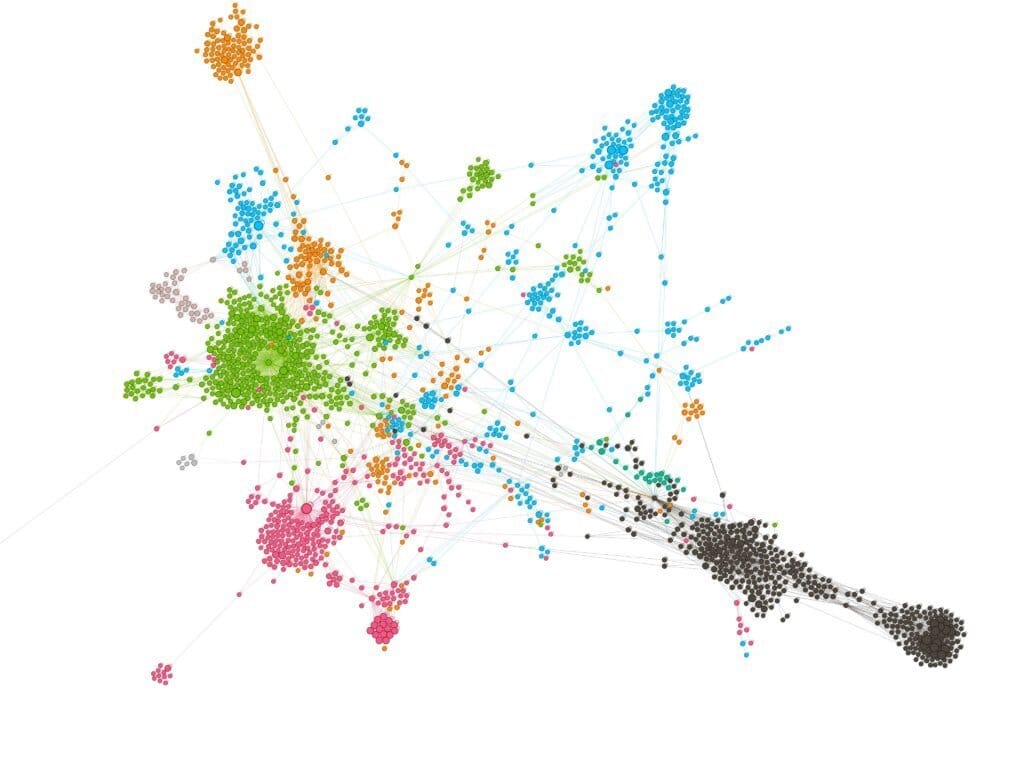
Once you know how to make these visualizations, I will give you some tips on what you can do with this information.
Let’s get started…
Why is Site Structure Important?
There are three major factors determined by the architecture of your website: 1) Crawlability, 2) PageRank flow, and 3) User experience.
Crawlability
This is the measure of how easy it is to visit all the pages of a website. Bots are smart, but even today’s algorithms don’t have any other way to visit a page than to follow a link. If the link path to some pages from the homepage is long, or there are no alternative routes, the page may be crawled rarely or even not at all!
PageRank flow
PageRank is one of the algorithms used by Google to determine a page’s value. Every page on the net shares a value with other pages via links. While you have no direct control over external links, you should do everything you can to provide a good internal “neighborhood” for your important pages. Pages in good neighborhoods compete better.
To be clear, we can only measure the internal flow of PageRank. Other factors, like external links, might influence it.
User experience
Have you ever visited a page and then couldn’t find it again when you wanted to revisit it? Have you ever been surprised to discover a “hidden section” of a website that was poorly linked? Or maybe you found yourself flooded with internal links? Structure analysis lets you easily identify parts of the website or page types that are linked poorly or extensively.
Gephi
What’s Gephi?
Tl;dr version: Gephi is cool. It’s a visualization tool for graphs that also allows for some graph operations.
What’s a graph? I believe every one of you has seen a graph in your life, probably in math class. Actually, for some of you, this might be the first time you will use the knowledge obtained in math outside of school!

A graph is a structure designed to present and explore the relations between data points. It contains nodes (data points) and edges (relations). Nodes are connected to each other by edges. This is a simple, but powerful idea. I know that no one likes math, but I’d like to point out that there is an actual field called graph theory. And Gephi allows us to use some of it without having to learn it (GREAT!).
OK, but I’ve got a website, not a graph! Yes, but a website can be presented as a graph. Every node represents a page, and edges are links.
Prerequisites: crawl data
You don’t need much to get started. Just a crawl of your website.
Grab your preferred crawler and look for the All Outlinks export option. I’m sure Screaming Frog (hereafter referred to as SF) provides that function (Bulk export -> All Outlinks), but it should also be included in other popular crawlers.
Now it’s time for filtering. Open the CSV file that you obtained using your favorite Excel-like program (for big sites I recommend Knime) and filter. You need to get rid of nofollow links. Bots do not follow those links (surprise!) so they do not count towards the structure. If you used an SF export, there is a Follow column with true/false values for you to use.
Got it? Good. Now filter some more. Actually, filter all the columns except the columns with the link’s source and target (source and destination in SF). Now you have to rename the columns to Source and Target. It’s a requirement imposed by Gephi – it seems that it just likes those names.
Before we can move on, you need to know that CSV files might contain something called BOM. This is just a character that indicates that the following bytes actually mean something (I know, I know, it’s not that simple, but whatever). Obviously, your Excel-like program wants everybody to know that the result file that it produced means something, so it placed a BOM character at the beginning of the file.
However, Gephi doesn’t recognize this BOM character, so it messes up the first thing that the file contains, which is the “Source” name. This needs to be fixed, but it’s not as easy as you may think. You will have to use a low-level editor. I recommend using Crimson Editor. Just load your file, select Document -> Encoding type -> UTF-8 (w/o BOM). Agree to reload the document and hit Ctrl+S to save the changes.
NOW we’re ready!
Just one more piece of advice: Remember to save your project regularly!
Step-by-step instructions
Import Data
If you followed my previous instructions, this step should be very straightforward. Select File -> Import Spreadsheet and choose your data file in the pop-up window. Now, you should see something similar to this:
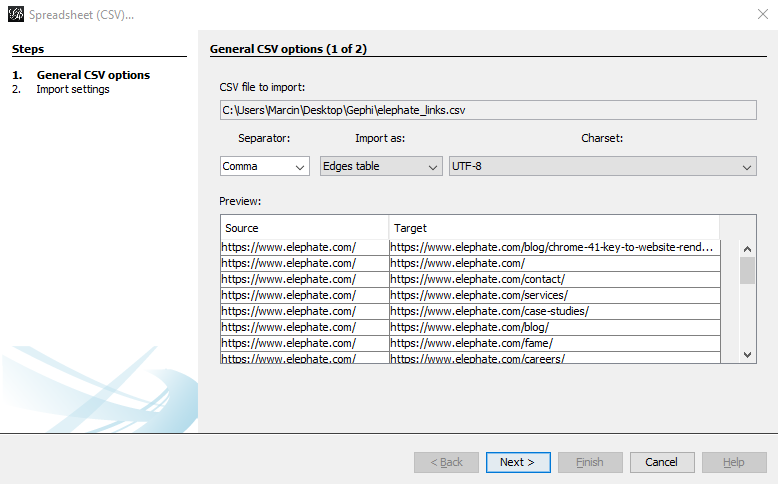
The important setting here is the Import as tab. There are 4 options available, but we are going to focus on two of them:
- Edges table – that’s the one we’re going to use. It allows you to import all edges (links). The nodes are created based on the starting- and end-points of the links.
- Nodes table – allows to import nodes and ties additional properties to them. We’re going to use it later.
Select Edges table, press Next, and finish the process on the next window. Now you are going to see the report window:
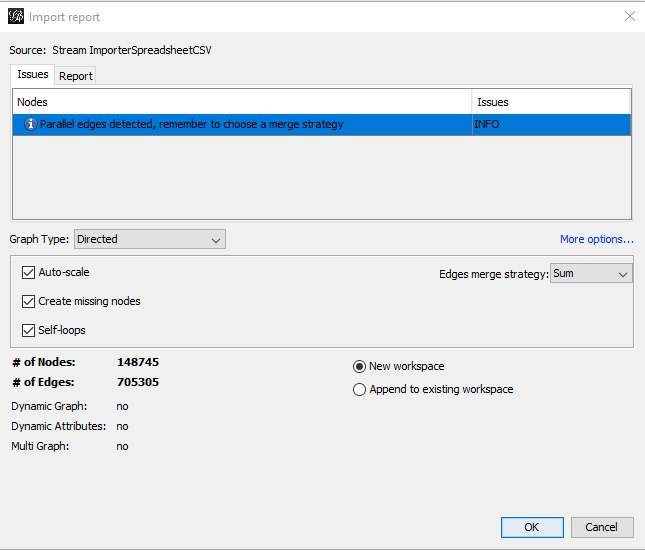
Parallel edges indicate that there are pages with multiple links to a single page. This is usually caused by navigation but might also occur in other scenarios. To resolve this, you have to choose Edges merge strategy, hidden under More options. The default Sum setting is OK for most uses (I will elaborate a little bit more about this in the “See Your Website through Google’s Goggles – PageRank Calculation” section below).
Checking the Self-loops option will allow you to see self-links on pages.
Leave all the other options default (unless you know what you’re doing).
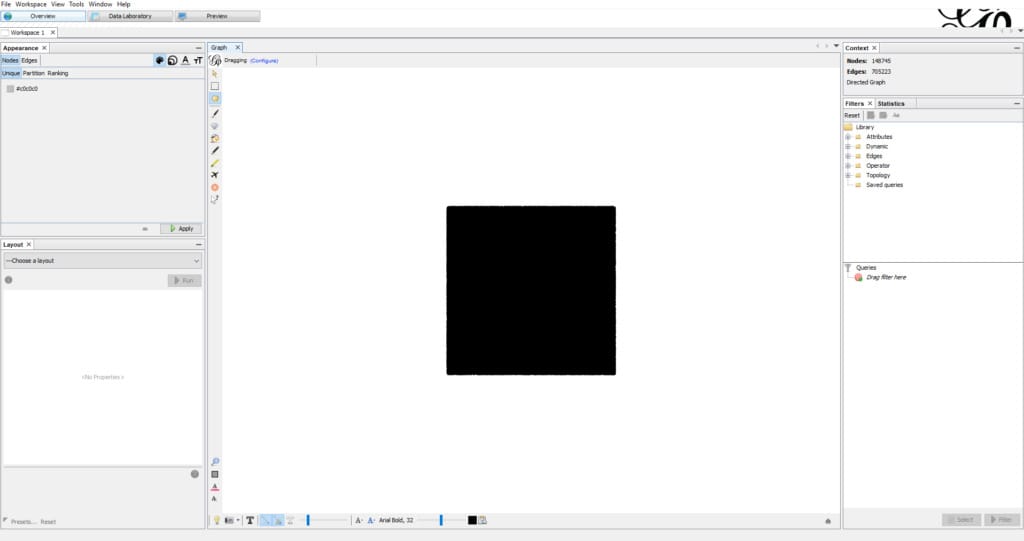
This is what you should see after the data is loaded:
Filtering (Optional)
If your site is big enough (let’s say >50k URLs ) you’ll want to filter out some pages. You want to apply filters until you’re comfortable with the number of pages (nodes) and links (edges). I’ve worked on a capable PC with ~100k nodes and ~1kk edges – and that was the verge of “comfortable” for me. Filters can be found in the right-hand side menu. You will be interested in the topology filters, so expand that part of the filters tree:
- Giant component – this will filter all the pages that are not part of the structure. Are there pages in the sitemap not linked anywhere on your site? Then you don’t necessarily want them here.
- Out degree range – the number of outlinks a page has. You want this to be greater than zero. Pages with no outlinks will not be important in the structure analysis. Also, narrow it down from the top; if you see pages with thousands of outlinks, it’s most likely your sitemap file.
- In degree range – The number of inlinks. If the graph still contains too many links/pages try to exclude pages with zero inlinks.
To set filters you simply drag and drop the first filter from the Library to the Drag filters here feature underneath the Filters section, and subsequent filters to Drag subfilters here, accessed by expanding the previous filter.
Be aware that the order of filters matters!
When you’re done, hit that Filter button with the green arrow and watch the number of nodes and edges fall (in the upper-right corner).
Statistics
Gephi allows us to calculate the number of graph statistics that we’ll use in our data presentation. You can access statistics by pressing the Statistics tab on the right-hand side menu, located next to the Filters tab.
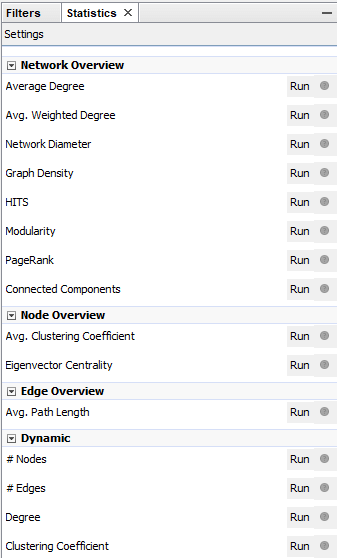
We want to calculate (by pressing the associated Run button) the following statistics from the Network Overview tab:
- Average Degree – no options here, simply run it.
- Network Diameter – select the Directed edges option in the popup window.
- Modularity – this will divide the graph into parts. The number of parts should be equal to the number of sections in your website. You’ll have to adjust the Resolution parameter in a trial and error process to make the numbers match.
Now we would like to apply some calculated properties to our nodes. We can do this with the Appearance tab on the left-hand side menu. There are two things that we want to alter: the size and the color of the nodes. In the Color section, select Partition and then Modularity Class from the drop-down menu (presented in the image below). If you’re not happy with the auto-generated color palette, you can create your own with the Palette… button.
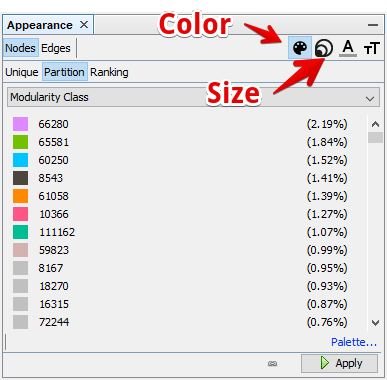
The second thing that we want to alter is the size of nodes. Go to the Size section (as you can see in the above image). Choose the Ranking tab this time and pick In-Degree from the drop-down menu. For min and max sizes, start with something like 1 – 10 and adjust later when needed. Hit the Apply button and watch your graph change (you won’t see much yet, but we’re very close!).
Layout
The last obligatory step is to create the layout of the graph. You have seen the black blob (or square) in the middle section – that’s your data. It changed colors and size when you altered the appearance, now we’re going to spread it out (below is an early stage of spacing a graph).

So, in order to space out your nodes (pages), we have to take a look at the Layout section on the left-hand side menu. For big sites, your only real option from the drop-down menu is ForceAtlas 2, as it is the fastest spacing method.
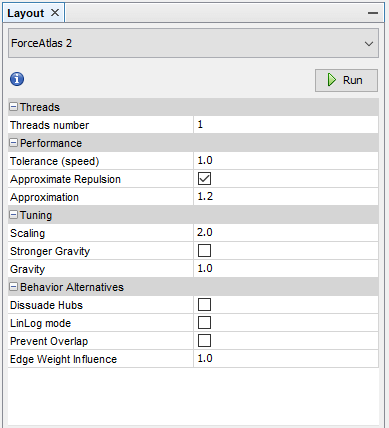
Here you’ll find some options. Increase the Threads number to the number of processor cores you have minus one (for visualization). The Performance section should be left as is by default unless you’re having problems with, well, performance. In such cases, increasing Tolerance and Approximation will decrease the time of algorithm execution. Tuning is the most important tab here. The settings will decide what your graph looks like, unfortunately, I can’t give you any pre-sets because every graph is different. The general rules are: Scaling will increase the size of the whole graph, and Gravity will make the clusters of pages tighter.
You run the algorithm by pressing the Run button. The changes you make here will have an immediate effect on the algorithm, so I encourage experimenting with scaling and gravity to get the best-looking graph. Don’t be afraid to set seemingly crazy values, some graphs are printed fine with low scaling values, while others require this value to be around a thousand! At the end of the process which may take a few minutes, check the Prevent Overlap option and let it run for a while longer. It won’t stop on its own, you have to terminate it by pressing the Stop button when you’re happy with the results.
Here’s an example of how the final results might look:
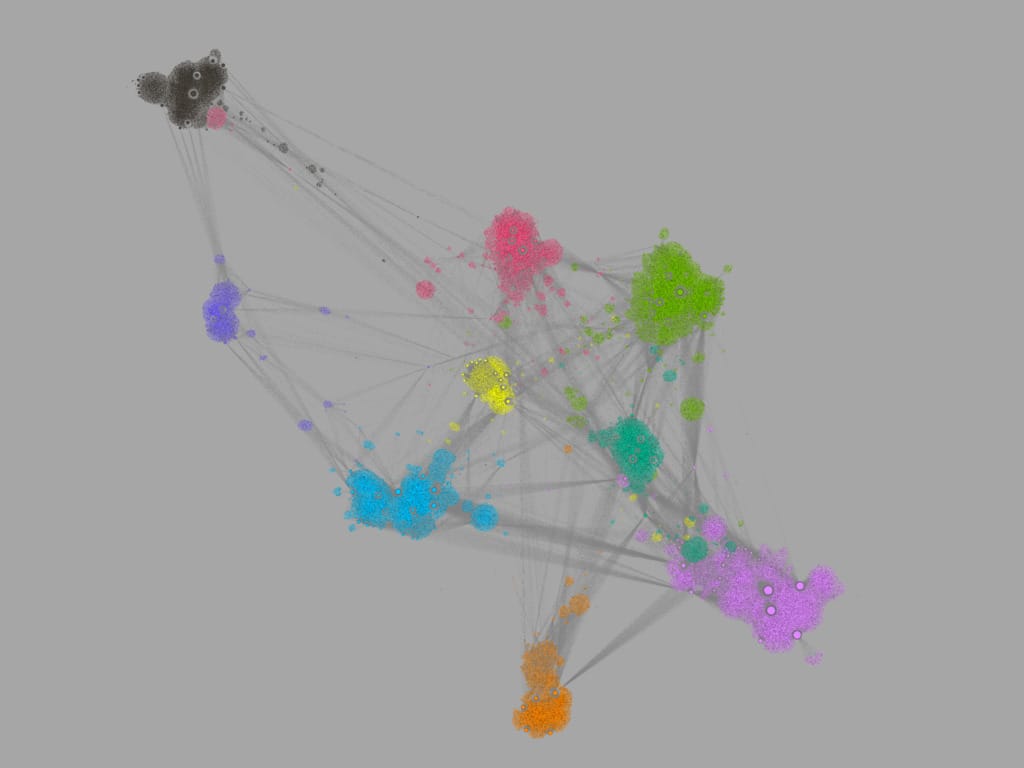
Other Tweaks
You may not be fully satisfied with what you’ve got, but don’t be afraid. Here are some tips on how to improve your graph.
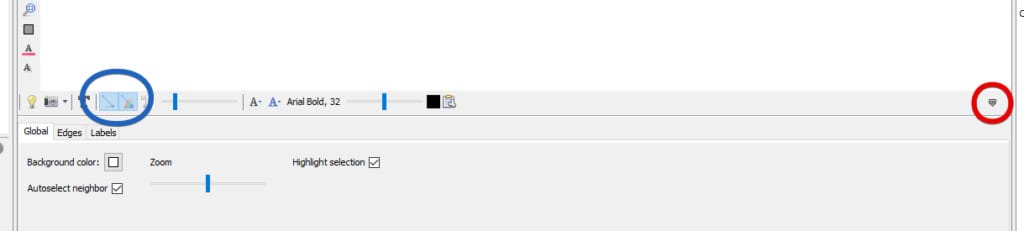
The small arrow-like button marked with red reveals a hidden menu with visual options!
In the Global tab you can change the background color (dark backgrounds look particularly good). The Edges tab allows you to change the width of the edges – a super handy option for dense graphs, but the true value lies in the Labels tab. Obviously you want to add labels to your nodes in order to know what page you’re looking at. For small graphs, you can go straight for all labels, but everything above a few dozen pages will be flooded with labels and become unreadable.
The solution? Create labels that are displayed when you hover your mouse above the node or select it. For this to happen, check the boxes by the Node and Hide non-selected options. You want to go to the Configure menu and tick the box by the Id option, and untick all the other boxes.
The last piece of advice here: if your graphic card is having a hard time displaying the graph, you may turn off edges by unchecking the two related options, marked with a blue circle in the above picture.
See Your Website through Google’s Goggles – Pagerank Calculation
PageRank is the backbone algorithm that lies at the foundation of Google. The very simplified version (but not completely out of touch) of describing the algorithm goes like this:
every link carries a little bit of value (rank) from the source page to the target. The “little bit” is a percentage of the source pages’ rank. Thus links from highly ranked pages carry more value than from crappy ones.
There is a common misconception that Google stopped using this algorithm, but in reality, they just stopped publicly displaying its value (and that’s a huge difference!). Of course, its importance dropped since the early days of search engines, but it’s still a factor in page rankings.
We can use our graph to calculate the internal flow of PageRank, but there are some limitations to what we can do.
Limitations
We have only our internal links to work with, Google on the other hand has links from the whole web. It’s entirely possible that some of your pages are linked extensively in external sources. Such cases will not be mirrored in our calculation, and this will affect not only the one page, but the structure of flow in a wider range. Nevertheless, you DO want to calculate the general structure of PageRank flow and act accordingly.
For example, if you could spot that PageRank is accumulated on your content pages instead of the pages that provide conversion, there’s probably potential to optimize internal linking.
So can Gephi do it for me?
Short answer: Yes, it can.
There are two paths to implement PageRank into your graph. You can calculate it internally, based on links from a crawl, or you can import an externally-calculated PageRank.
If you’d like to calculate PR on your own, there’s one main difficulty: link weights. It’s clear that sitewide links are treated differently by Google – that means their weight should be lower. But how much exactly? 0.2? 0.3? 0.5? There’s no definitive answer, you’d have to go with your gut feeling (or try to find some other source). Also, it’s not clear how parallel links are treated. At the beginning in the Crawl Data sections, we’ve summed the weights, but is that correct? I don’t know. Nevertheless, with all that uncertainty you can still guess the values and create a meaningful representation, which might be slightly off-hand, but will show you the general structure of the PageRank flow.
OK, so here’s how to do it:
First of all, you should identify sitewide links. The easiest way to do it? Take your crawl data and group it by the target URL and count the number of occurrences (this is easy using Knime). Now add to your crawl data a new column named “Weight” and set its value to “1” for all the non-sitewide links, and *your guessed value* (I’d go with 0.4) for the rows with a sitewide link in the “Target” column. Now, we’ve reduced the value of all sitewide links, but also for all other links to those pages! We have to revert that change for duplicate rows (a duplicate row means that there are at least 2 parallel links, only one of which is sitewide). You can easily find duplicate rows using Excel’s Conditional formatting -> Duplicate rows.
Now, import the extended crawl data to Gephi. My guess is that Google is using some logarithmic sum for parallel links merging that converges to a set max value, but if your site doesn’t contain LOTS of parallel links, you should be just fine using simple SUM as Edges merge strategy. Now the calculation. You can find it under the Statistics tab in the Network Overview section. It’s called PageRank. Make sure you’re using the Directed setting, and the Use edge weight box is ticked. For big sites, you can increase the Probability (p) parameter to around 0.95, but it’s not necessary, and shouldn’t have a huge impact on the outcome of the algorithm.
The second way to do it is to import PageRank values from an external source. Some tools (for example, Ryte) can calculate PageRank for you (in the case of Ryte, this metric is called OnPageRank, but is essentially very similar to PageRank). You’d have to export all the pages with the PR metric. You should then clean your data, and leave just two columns: one with the pages’ URL (set its name to “Id”) and the second with the PageRank metric (name it “PageRank”). Then you should be able to import this spreadsheet to your existing graph. While importing, use the Nodes table setting under the Import as tab, and in the Import report window, select the Append to existing workspace option.
And finally, to make the values visible, change the nodes size setting in the Appearance section from In-Degree to PageRank.
Before we move on, here is an example of an analysis I once did with a calculated PageRank, where the marked pages had accumulated a significant amount of PageRank:

Bonus! Crawling Heatmap
What Are Those?
If you’re concerned with SEO, you have surely worked with, or at least heard about, server log analysis, right? One of the reasons to check logs is to find out what parts of your website are visited by Google. There are, of course, well-written tools that help you identify the structure of crawling, but wouldn’t it be great to just see the crawling frequency printed on a graph that represents your whole site? You’d be able to see all the big-scale features of the crawl immediately, at one glance.
How do you prepare one?
It’s not as difficult as you may think. First of all, we need data. Let’s assume that your log files are constructed with the Common Log Format, which goes like this:
| 127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] “GET /apache_pb.gif HTTP/1.0” 200 2326 |
127.0.0.1 – this is the client’s IP address which is how you want to identify Google. There are complete lists of IPs owned by Google, but as a rule of thumb you should be OK with filtering for 66.249.*.*
The other important part is the path contained within “GET [Path] HTTP” – we will reconstruct the whole URL based on this.
To filter and extract the file, we’ll use the BASH command line (default console on Linux, Cygwin is a simulator for Windows). For simplicity, name your log file ‘logs’ and put it into the /log/ folder in your partition root folder (C:log for example) Here are the commands you will need:
| cd C:/logs/
grep “66.249” log.* > filtered.log grep -oP “(?<=GET).*(?=HTTP)” filtered.log > urls.log |
Now you should switch to Knime (or Excel, if you prefer) and do a group by, grouping identical URLs together and counting the number of occurrences. Afterward, rename the columns to “ID” and “Events” and save them as CSV. This is how the prepared file should look:
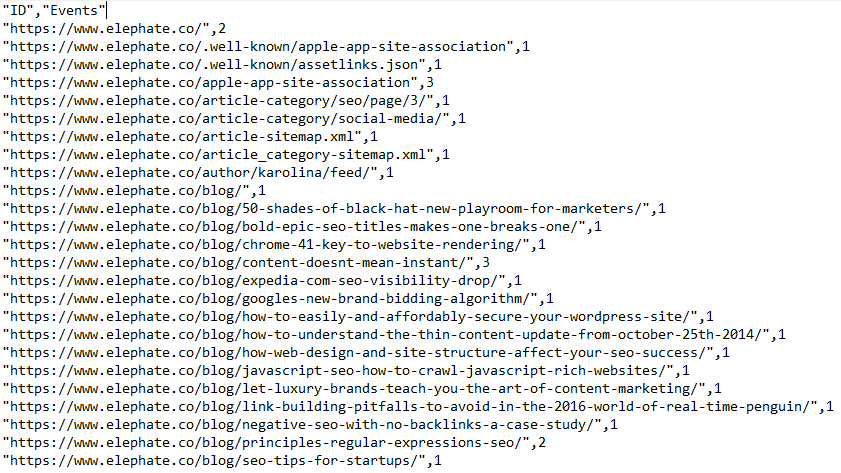
Now, open your project in Gephi and import your prepared log file using Import Spreadsheet. In the Import as menu, pick Nodes table, and in the report windows choose the Append to existing workspace option.
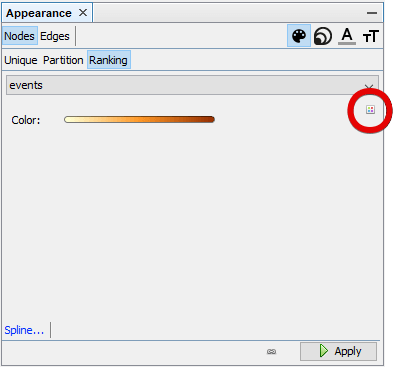
Finally, you can color your nodes using the log data. Go to the Appearance section, and after choosing Nodes, Color, and Ranking, pick Events. You may change the color scheme used for ranking by clicking on the color palette (marked with a red circle below). You may also check the Spline… option. It allows making the color change non-linear, which can be used to highlight some features of the graph (for example, making URLs with 0 events more distinct).
Here’s a graph presenting our Onely website with some hints on what to look for. It’s a very small website, so the structure is not very complicated, but nevertheless, you can spot some features right away.

Wrapping Up
At first, this might all seem complicated and difficult, but it’s really not that hard. Just follow the steps I’ve outlined here and you’ll be fine.
My experiences working with graphs on Gephi have always been pleasant. The graphs are sometimes truly beautiful and tweaking the parameters to get the most of them feels almost like art. Just remember that this isn’t about creating beautiful images, but obtaining important data about site structures.
If you have any questions or want to share your experiences with Gephi, please don’t hesitate to leave your comments below. I will be more than happy to help or maybe even learn something I’ve missed! You can also contact us and take advantage of Onely’s technical SEO services.







