
What is JavaScript SEO?
JavaScript SEO is a part of technical SEO that makes Javascript-powered websites easy for search engines to crawl, render, and index.
JavaScript SEO can make modern websites more user-friendly and rank higher on Google by:
- optimizing JavaScript-powered elements for your pages’ efficient discovery,
- identifying and troubleshooting any issues that make it difficult for search engines to understand and process your JavaScript content, and
- minimizing JavaScript’s influence on your website’s web performance and user experience (UX).

JavaScript is extremely popular. Based on my research from 2019, as much as 80% of the popular eCommerce stores in the USA already used JavaScript for generating main content or links to similar products back then. In 2023, I’d expect that number to be even higher.
However, many JavaScript websites – despite JavaScript’s popularity – underperform in Google because they don’t do JavaScript SEO properly.
In this article, I will guide you through why it’s happening and how to fix it. You’ll learn the following:
- how Google and other search engines deal with JavaScript,
- how to check if your website has a problem with JavaScript,
- what are the best practices of JavaScript SEO, and
- the most common problems with JavaScript that SEOs overlook.
I will provide tons of additional tips and recommendations, too. We have a lot to cover, so get yourself a cup of coffee (or two), and let’s get started.
Contents





How does JavaScript affect SEO?
In 2023, there’s no doubt that JavaScript is a fixed part of the web.
Of course, HTML and CSS are the foundation of the web. But virtually every modern web developer is expected to code in JavaScript too.
But what can JavaScript do, exactly? And how does it affect SEO? Read on, and you’ll find out.

JavaScript is an extremely popular programming language. Developers use it to make websites interactive.
It means you can build a website using only HTML and CSS, but JavaScript makes it dynamic and interactive.
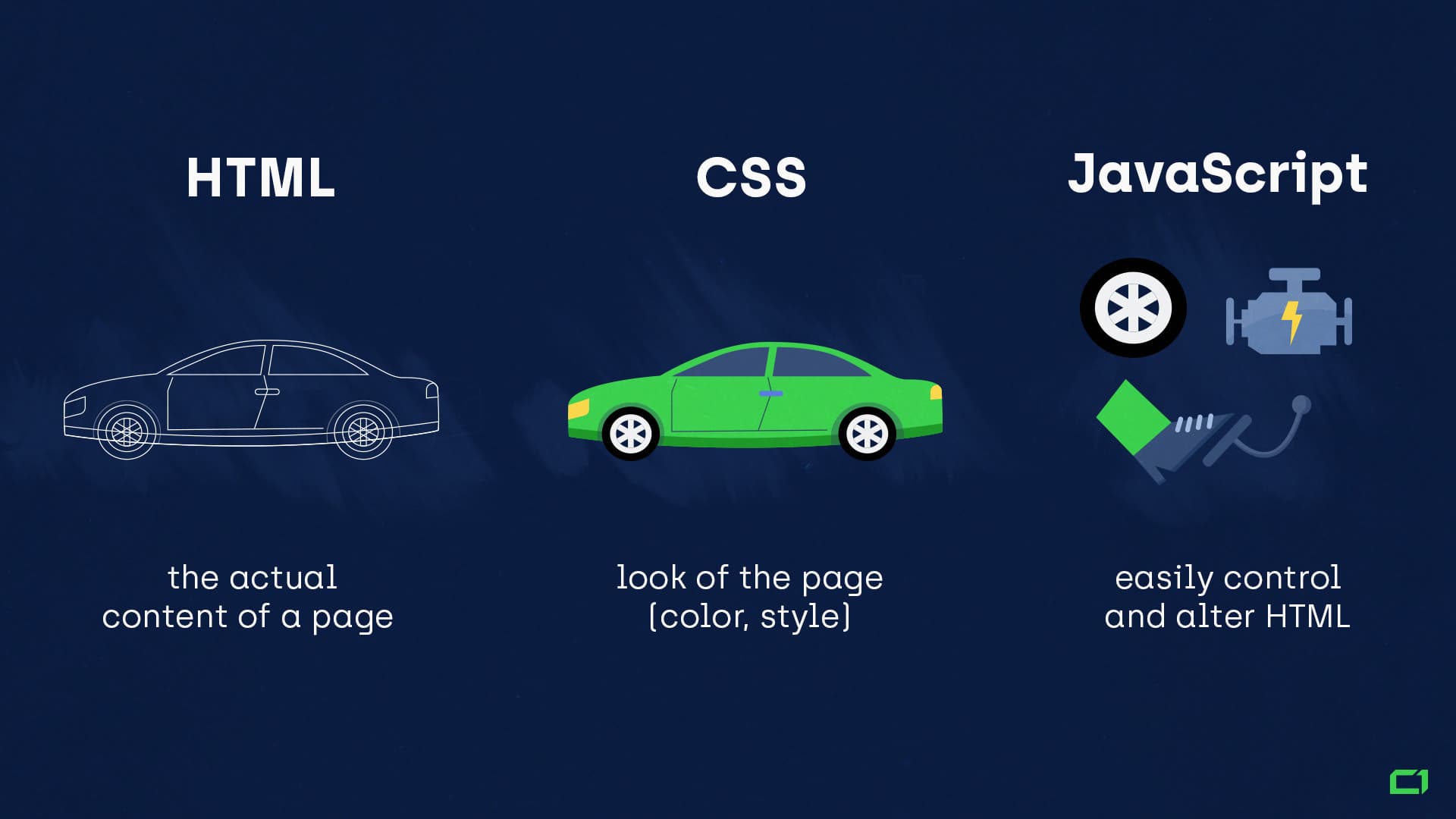
- HTML defines the actual content of a page (body/frame of a car.)
- CSS defines the look of the page (colors, style.)
- JavaScript adds interactivity to the page. It can easily control and alter HTML (engine + wheel + gas pedals.)
However, what’s more important from the SEO perspective is that using JavaScript can affect two vital aspects of your website ‒ its indexing pipeline (crawling, rendering, and indexing) and web performance.
Because of its additional complexity, JavaScript makes it more difficult for Google to crawl, render, and index JavaScript-powered pages than, e.g., pure HTML.
What does it mean for you? That creating JavaScript-heavy pages without guidance and proper expertise may backfire on your index coverage.
Then, from the web performance perspective, leaving your JavaScript unoptimized will negatively affect how fast your website is, which, in turn, will directly translate to a poor user experience.
Optimizing JavaScript is necessary if you care about your website’s SEO and business development.
Is JavaScript bad or good for SEO?
Over the years, I’ve seen many people searching for information on whether JavaScript usage positively or negatively impacts SEO. Unfortunately, there’s no clear-cut answer to this question.
JavaScript makes diagnosing SEO issues much more difficult. You don’t have a guarantee that Google will execute your JavaScript code on every page of your website.
But let me put it this way: JavaScript is not evil. Unoptimized JavaScript may hurt your SEO rankings, but it doesn’t mean you should avoid using it.
JavaScript puts an extra layer of effort that you need to put into your website to make it successful on Google.
More importantly, JavaScript is an essential element of the modern web, just like HTML and CSS. It’s not going away, so you should face that challenge rather than run away from it.
JavaScript has the unique ability to update the content of a page dynamically. That’s why, when properly optimized, JavaScript can bring numerous benefits to your website, especially from the user experience perspective.
For instance, it’s used by Forex and CFD trading platforms to continually update the exchange rates in real-time.
Now, imagine a website like Forex.com without JavaScript.
Without JavaScript, users must manually refresh the website to see the current exchange rates. JavaScript simply makes their lives much easier.
Also, JavaScript may be responsible for generating such common website elements and types of content, like:
- pagination,
- internal links,
- top products,
- reviews,
- comments,
- main content (rarely.)

In 2023, it’s difficult to imagine a website without these interactive elements that help users flow through your pages. Of course, you can build a website without JavaScript, but it would significantly limit its functionality and interactivity.
That’s why even if you’re encountering some JavaScript-related issues, it doesn’t mean you should get rid of using it and switch to a different technology.
Using JavaScript on a modern website should be more of a question of ‘how’ you can optimize JavaScript for bots and users, rather than ‘if’ you should use JavaScript.
The good news is that many websites using JavaScript are doing exceptionally well. In her article for Moz, a colleague of mine, Justyna Jarosz, described real-life examples of websites that managed to (and did not) avoid common JavaScript mistakes.
Now that you know there’s no need to demonize using JavaScript, it’s time to find out how Google processes your JavaScript content. Let’s dive in.
How does Google read and render JavaScript websites?
You now know that JavaScript makes Google’s job a little more complicated.
And because of that, there are additional steps that you should take to make your JavaScript website do well in Google.
JavaScript SEO may seem intimidating at first, but don’t worry! This chapter will help you diagnose potential problems on your website and get the basics right.

There are three factors at play here:
1) crawlability (Google should be able to crawl your website with a proper structure and discover all the valuable resources),
2) renderability (Google should be able to render your website,
3) crawl budget (how long it will take for Google to crawl and render your website).
In the meantime, many things can go wrong with rendering JavaScript. As the whole process is much more complicated with JavaScript involved, the following things should be taken into account:
- Rendering JavaScript can affect your crawl budget and delay Google’s indexing of your pages.
- Parsing, compiling, and running JavaScript files is time-consuming for users and Google. Think of your users! I bet 20-50% of your website’s users view it on their mobile phones.
How long does it take to parse 1 MB of JavaScript on a mobile device? According to Sam Saccone from Google: Samsung Galaxy S7 can do it in ~850ms and Nexus 5 in ~1700ms. After parsing JavaScript, it has to be compiled and executed, which takes additional time. Every second counts.
- In the case of a JavaScript-rich website, Google usually can’t index the content until the website is fully rendered.
- The rendering process can also take longer than usual which impacts the process of discovering new links. With JavaScript-rich websites, it’s common that Google cannot discover any links on a page before the page is rendered.
JavaScript crawling
Using JavaScript adds even more complexity to the crawling process. Why? Because when unoptimized, JavaScript:
- may not allow Google to discover and access all your pages, e.g., by making your internal linking invisible to bots, and
- makes it more difficult for Googlebot to understand how your pages are related and what they are about because, e.g., bots can’t access the main content of your pages
In fact, our recent research shows that Google needs 9x more time to crawl JavaScript-powered websites vs. plain HTML.
You need to know that the number of pages Googlebot wants to and can crawl is called the crawl budget. Unfortunately, it’s limited, which is essential for medium to large websites and those heavily relying on JavaScript. This is something crawl budget optimization services typically deal with.
If you want to know more about the crawl budget, I advise you to read the ultimate guide to crawl budget by Artur Bowsza, Onely’s SEO Specialist.
Also, I recommend reading Barry Adams’ article on JavaScript and SEO: The Difference Between Crawling and Indexing. In particular, take a look at the JavaScript = Inefficiency and Good SEO is Efficiency sections, which are must-haves for every SEO who deals with JavaScript.)
JavaScript rendering
There are several ways of serving your web pages to users and search engines.
And understanding them is crucial when we are talking about SEO, not exclusively in the context of JavaScript.

Let’s use the baking analogy here. The initial HTML is just a cooking recipe. It provides information about what ingredients you should use to bake a cake. It contains a set of instructions. But it’s not the actual cake.

On the other hand, there’s the DOM (Document Object Model) – the rendered code, which represents the state of your page after rendering.
DOM is the actual cake. In the beginning, it’s just a recipe (an HTML document), and then, after some time, it gains a form, and then it’s baked (page fully loaded.)
If Google can’t fully render your page, it can still index just the initial HTML (which doesn’t contain dynamically updated content.)
What it means for you is that, in the case of an unoptimized JavaScript-rich website, Googlebot may not see the crucial content you want to get indexed and rank for.
As we discuss whether Google can crawl, render, and index JavaScript, we must address two important concepts: server-side rendering and client-side rendering. It’s necessary for every SEO who deals with JavaScript to understand them.
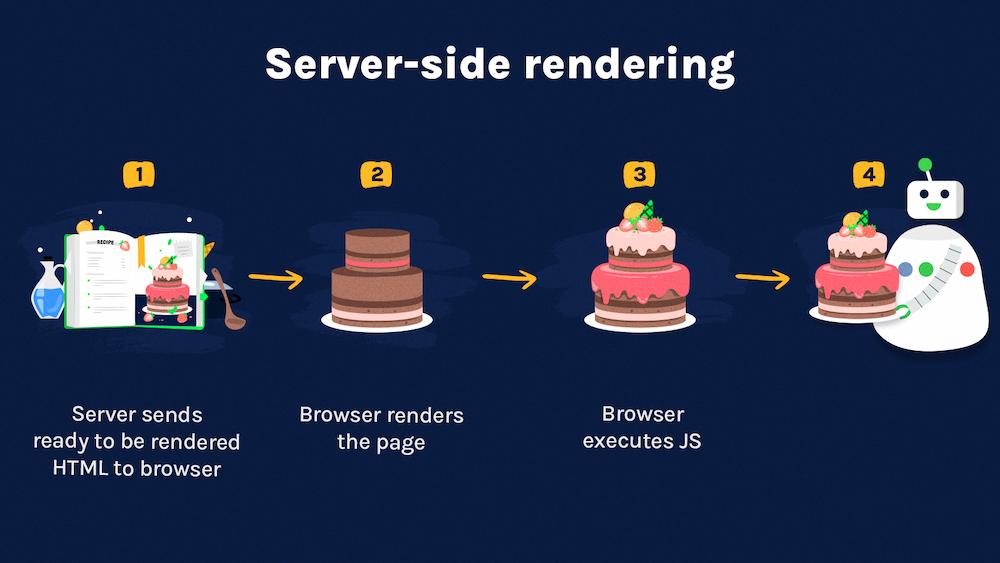
Server-side rendering
In server-side rendering, a browser or Googlebot receives an HTML file that completely describes the page. The content copy is already there.
Remember our baking analogy? It’s valid here as there’s no need for baking in server-side rendering ‒ Google gets the cake ready to consume.
Usually, search engines do not have any issues with server-side rendered JavaScript content.
There is one problem, though: it may happen that without SEO guidance some developers may struggle with implementing server-side rendering properly.
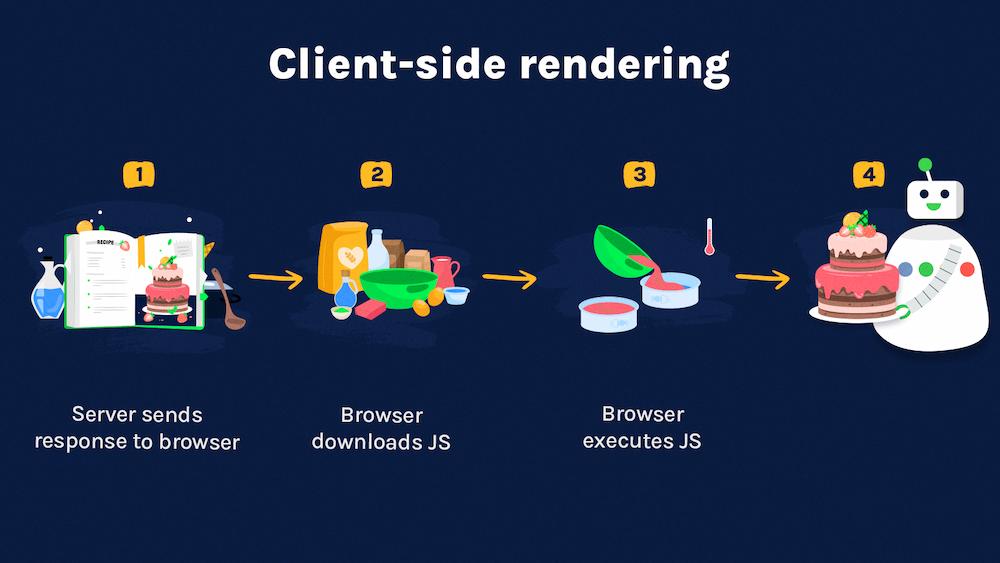
Client-side rendering
With client-side rendering, a browser or Googlebot gets a blank HTML page (with little to no content copy) in the initial load. Then the magic happens: JavaScript asynchronously downloads the content copy from the server and updates your screen.
According to our baking analogy, client-side rendering is like a cooking recipe. Google gets the cake recipe that needs to be baked and collected.
Unfortunately, search engines sometimes struggle with this approach. Why? Because for bots, it might be more expensive to process JavaScript on their side than to receive a server-side rendered version of pages.
What browser is Google currently using for rendering web pages?
Google is using the most recent version of Chrome for rendering (it’s called Googlebot Evergreen.)
There might be a slight delay with introducing the new version of Chrome, but the workflow is that whenever Google Chrome gets an update, Googlebot gets an update straight afterward.
How do other search engines read JavaScript websites?
In 2019, my research showed that indexing JavaScript content is still never guaranteed. But what is even worse, if your JavaScript content is not indexed, it may lead to your whole page not being indexed, too.
Google is quickly improving its ability to process and index JavaScript at scale, but there are still many caveats to watch out for, and that’s why my ultimate guide became so popular.
But you must remember that other search engines (and social media) are far behind Google regarding available resources and technology.
If any of your website’s content depends on JavaScript, you must ensure that search engines can easily access, render, and index it.
Can social media platforms like Twitter and Facebook render JavaScript?
Unfortunately, social media sites don’t process JavaScript their crawlers find on websites. To reiterate, social media like Facebook, Twitter, or LinkedIn don’t run JavaScript.
What does that mean for you?
You must include Twitter Cards and Facebook Open Graph markup in the initial HTML. Otherwise, when people share your content on social media, it won’t be properly displayed.
Not convinced?
Let’s see how links to Angular.io and Vue.js look when you share them on Twitter:
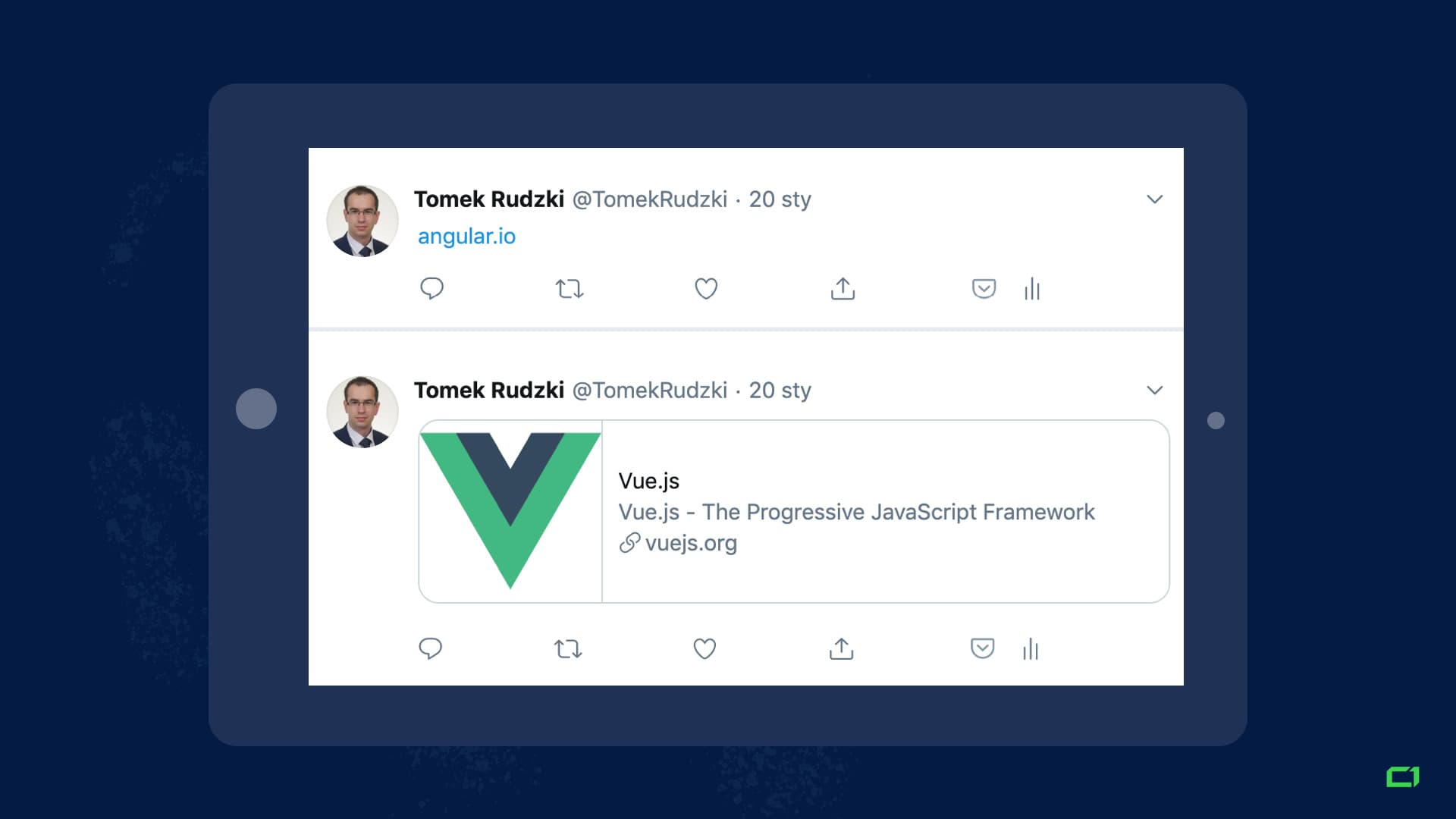
Angular.io is the second most popular JavaScript framework. Unfortunately for them, Twitter doesn’t render JavaScript, and therefore it can’t pick up the Twitter card markup that JavaScript generates.
Would you click on that link? Probably not.
Now contrast that with a link to Vue.js ‒ the Twitter card looks much better with the custom image and an informative description!
Takeaway: If you care about traffic from social media, make sure that you place the Twitter card and Facebook Open Graph markup in the initial HTML!

What if Google cannot render your page?
Google may render your page in an unexpected way.

Looking at the image above, you can see a significant difference between how the page looks to users and how Google renders it.
There are a few possible reasons for that:
- Google encountered timeouts while rendering.
- Some errors occurred while rendering.
- You blocked crucial JavaScript files from Googlebot.
Important note: making sure Google can properly render your website is necessary.
However, it doesn’t guarantee your content will be indexed. This brings us to the second point.
Can Google index JavaScript?
JavaScript makes the web truly dynamic and interactive, and that’s something that users love.
But what about Google and other search engines? Can they easily deal with JavaScript, or is it more of a love-hate relationship?
As a leading technical SEO agency, we constantly research Google’s strengths and weaknesses.
And when it comes to JavaScript, it’s sort of a mixed bag…

In general, Google can index JavaScript. However, indexing JavaScript content by Google is never guaranteed.
Based on our research from 2019 on using JavaScript by popular websites, it turned out that, on average, JavaScript content was not indexed by Google in 25% of the cases.
That’s one out of four times.
Here are some examples of the tested websites:
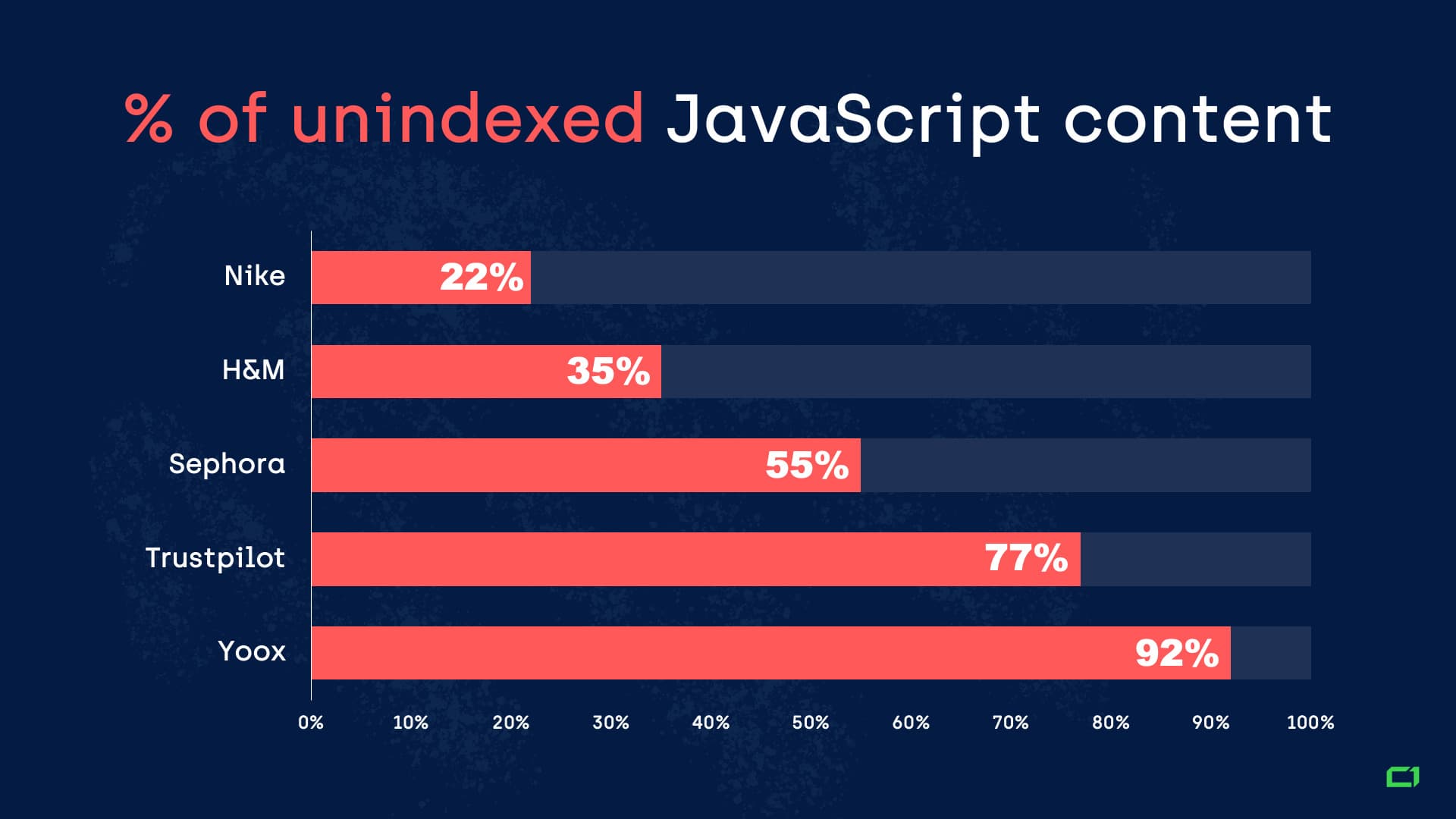

On the other hand, some of the websites we tested did very well:
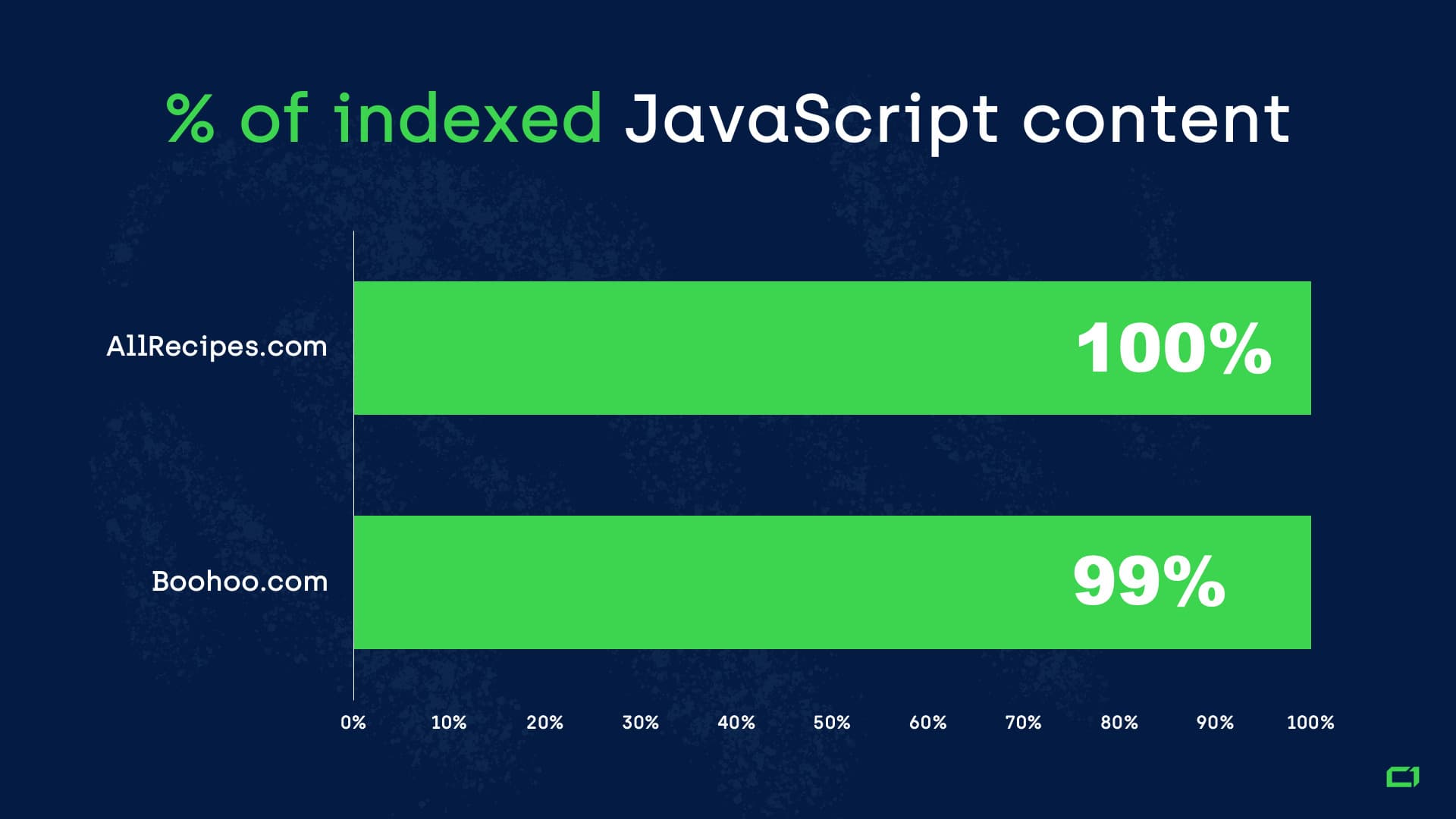
As you can see, Google can index JavaScript content on some websites much better than others. This means that these issues are self-induced and can be avoided. Keep reading to learn how.
How to check if your JavaScript content is indexed in Google?
There are two ways to check if your JavaScript content is indexed in Google:
- Using the “site:” command ‒ the quickest method.
- Checking Google Search Console ‒ the most accurate method.
To begin with, use the “site:” command to check if the URL is in Google’s database.
Then check if Google indexed your JavaScript content.
Knowing which fragments of your page depend on JavaScript (you can use our tool, WWJD, to identify them), copy a JavaScript-injected text fragment from your page and type the following command in Google: site: your website’s URL “fragment.”
If a snippet with your fragment shows up, your content is indexed in Google.
My recommendation: perform a “site:” query with a fragment in incognito mode across various types of JS-generated content.
On the other hand, a more precise, albeit slower, method of checking if Google indexes your content is using the URL Inspection tool in Google Search Console.
The tool will show you the code of your page indexed in Google, so you can just Ctrl+F to see if the crucial fragments of your content generated by JavaScript are here.
I recommend repeating this process for a random sample of URLs to see if Google properly indexed your content. Don’t stop at just one page; check a reasonable number of pages.
What about other popular methods like, e.g., checking Google Cache? Even though many SEOs still use it, relying on Google Cache is a bad idea to check if your JavaScript content is indexed in Google.
You can learn more by reading “Why Google Cache Lies to You and What To Do” by Maria Chołuj (Cieślak), Onely’s Head of SEO.
What if Google doesn’t index my JavaScript content?
As I mentioned before, the problems that some websites have with getting their JavaScript content indexed are largely self-induced. If you struggle with such a problem, you should find out why it might be happening in the first place.
There are multiple reasons why Google didn’t pick up your JavaScript content. To name a few:
- Google encounters timeouts. Are you sure you aren’t forcing Googlebot and users to wait many seconds until they can see the content?
- Google had rendering issues. Did you check the URL Inspection tool to see if Google can render it?
- Google decided to skip some resources (i.e., JavaScript files.)
- Google decided the content was of low quality.
- It may also happen that Google will index JavaScript content with a delay.
- Google simply wasn’t able to discover this page. Are you sure it’s accessible via the XML sitemap and the internal structure?
However, getting to the core of your problems is half a battle. And while your JavaScript issues store up, trying to figure out what aspects you should address first can give you a real headache.
The good news is you don’t need to deal with such chaos on your own. Reach out to us for our JavaScript SEO services where we can offer you a step-by-step action plan to increase the index coverage of your JavaScript content.
What about the two waves of indexing?
In 2018, Google announced they were using a system of two waves of indexing. This meant that they partially indexed content directly available in the HTML file and indexed the rest of the content when appropriate resources were available ‒ with a delay.
This indexing strategy particularly affected indexing JavaScript-generated content as it’s very resource-consuming.
Bartosz Góralewicz, Onely’s CEO, discussed the topic of Google’s two waves of indexing with Martin Splitt and John Mueller in 2019.
Back then, Martin Splitt stated that the two waves of indexing weren’t gone, but they played less of a role than they had in the past.
And I wouldn’t say that two waves of indexing are dead […] They’re absolutely not, but it’s definitely – I expect, eventually rendering, crawling and indexing will come closer together. We’re not there yet, but I know the teams are looking into it.
In 2020, Martin Splitt updated this information by saying that “you can also still use the two waves of indexing as a simplification for the process. It’s just more complicated behind the scenes.”
[…] That was specifically aimed at “two waves”. That is an oversimplification. FWIW as a developer or SEO I would just assume my pages get rendered and get on with it 🙂 […]
In other words, this proves that the ‘two waves of indexing’ can no longer be interpreted as the same as a couple of years ago.
Also, Martin Splitt dived into a more detailed explanation in the Search Off the Record podcast:
I was convinced back then that, yeah, that’s [the two waves metaphor] a fantastic way of explaining how things work in rendering and indexing and crawling because it’s such a complicated process with lots of things happening in parallel. […] The way that we are seeing it, most cases, and basically that’s nearly a hundred percent of the cases, your website gets crawled and it gets rendered and then it gets indexed. There are certain situations where that isn’t true, like when the rendering fails multiple times or when we have other signals that we can pick up from the initial HTML and stuff. So it isn’t necessarily that everything gets rendered, but pretty much practically every website gets rendered before it gets indexed.
JavaScript indexing delays
Although Google is getting better at it, as of the beginning of 2023, processing JavaScript content still involves a significant delay.
Based on the experiment of our R&D team, it turned out that Google needs 9x more time to crawl JavaScript than HTML pages.
This demonstrates the existence of a rendering queue at Google and how significantly it influences the crawling and indexing of JavaScript-generated content.
For more details, read Ziemek Bućko’s article about the rendering queue experiment.
Why Google (and other search engines) may have difficulties with JavaScript
Crawling JavaScript is not easy for Google
In the case of crawling traditional HTML websites, everything is easy and straightforward, and the whole process is lightning-fast:
- Googlebot downloads an HTML file.
- Googlebot extracts the links from the source code and can visit them simultaneously.
- Googlebot downloads the CSS files.
- Googlebot sends all the downloaded resources to Google’s Indexer (Caffeine).
- The indexer (Caffeine) indexes the page.
While many websites struggle with indexing issues even though they don’t extensively use JavaScript (and technical SEO services often address these issues), things get complicated when it comes to crawling a JavaScript-based website:
- Googlebot downloads an HTML file.
- Googlebot finds no links in the source code as they are only injected after executing JavaScript.
- Googlebot downloads the CSS and JS files.
- Googlebot has to use the Google Web Rendering Service (a part of the Caffeine Indexer) to parse, compile and execute JavaScript.
- WRS fetches the data from external APIs, from the database, etc.
- The indexer can index the content.
- Google can discover new links and add them to the Googlebot’s crawling queue. In the case of the HTML website, that’s the second step.
Googlebot doesn’t act like a real browser
It’s time to go deeper into the topic of the Web Rendering Service.
As you may know, Googlebot is based on the newest version of Chrome. That means that Googlebot is using the current version of the browser for rendering pages. But it’s not exactly the same.
Googlebot visits web pages just like a user would when using a browser. However, Googlebot is not a typical Chrome browser.
- Googlebot declines user permission requests (i.e., Googlebot will deny video auto-play requests.)
- Cookies, local, and session storage are cleared across page loads. If your content relies on cookies or other stored data, Google won’t pick it up.
- Browsers always download all the resources ‒ Googlebot may choose not to.

When you surf the internet, your browser (Chrome, Firefox, Opera, whatever) downloads all the resources (such as images, scripts, stylesheets) that a website consists of and puts it all together for you.
However, since Googlebot acts differently than your browser, it aims to crawl the entire internet and grab valuable resources.
The World Wide Web is huge, so Google optimizes its crawlers for performance. This is why Googlebot sometimes doesn’t load all the resources from the server. Furthermore, Googlebot doesn’t even visit all the pages it encounters.
Google’s algorithms try to detect if a given resource is necessary from a rendering point of view. If it isn’t, it may not be fetched by Googlebot. Google warns webmasters about this in the official documentation.
Because Googlebot doesn’t act like a real browser, Google may not pick some of your JavaScript files. The reason might be that its algorithms decided it’s unnecessary from a rendering point of view or simply due to performance issues (i.e., it took too long to execute a script.)
Also, rendering JavaScript by Google is still delayed (however, it is much better than in 2017-2018, when we commonly had to wait weeks till Google rendered JavaScript).
If your content requires Google to click, scroll, or perform any other action in order for it to get loaded onto the page, it won‘t be indexed.
Last but not least: Google’s renderer has timeouts. If rendering your script takes too long, Google may skip it.
How to check if your website has a problem with JavaScript
Google offers a variety of tools that can help you identify and diagnose your JavaScript-related problems. These are, for example:
Although some of the tools above aren’t directly connected with using JavaScript on your website, they still may be a great source of information on how Google processes your JavaScript content.
All you need to do is learn how to use these tools to audit JavaScript on your own or take advantage of JavaScript SEO services.
How do I know if my website is using JavaScript?
Before you dive into JavaScript optimization, you need to identify what elements on your website are JavaScript-generated.
I recommend you using the two following methods:
Use WWJD
To make it easy for you to check if your website relies on JavaScript, we created WWJD ‒ What Would JavaScript Do ‒ which is just one of our free JavaScript SEO tools.
Simply go to WWJD and type the URL of your website into the console.
Then look at the screenshots the tool generates and compare the two versions of your page ‒ the one with JavaScript enabled and the one with JavaScript disabled.
Use a browser plugin
Using our tool is not the only way to check your website’s JavaScript dependency. You can also use a browser plugin like Quick JavaScript Switcher on Chrome or JavaScript Switch on Firefox.
When you use the plugin, the page you’re currently on will be reloaded with JavaScript disabled.
If some of the elements on the page disappear, it means that they were generated by JavaScript.
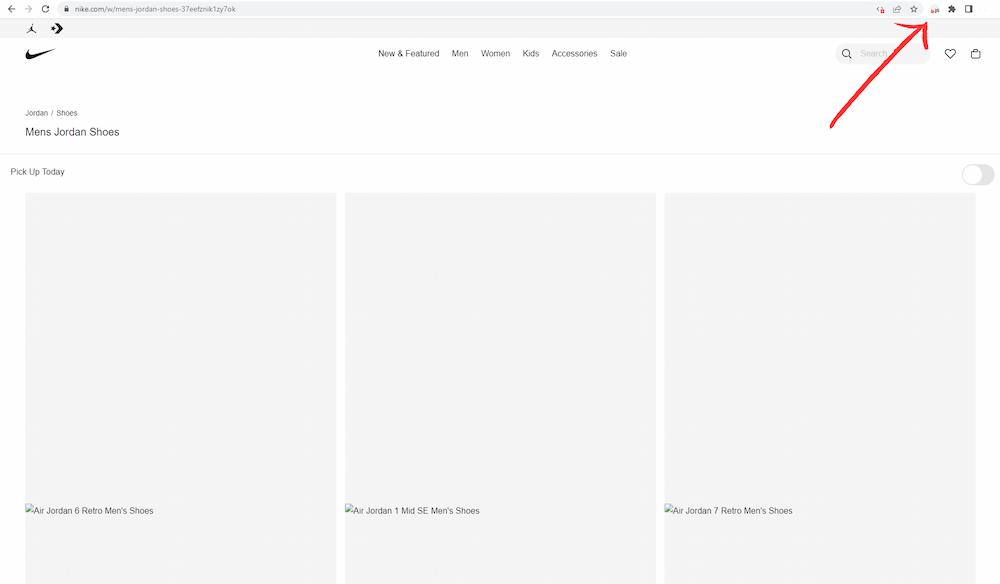
Take a look at how the product page of nike.com looked like when I used the Quick JavaScript Switcher extension to disable all JavaScript-powered elements:
JavaScript Best Practices for SEO
At this point, you should understand how Google and other search engines process JavaScript.
Now that we’ve covered most of the basics, let’s look at some of the best practices SEOs and webmasters should strive for when optimizing their JavaScript-based websites.
Best practices for JavaScript SEO include the following:
- Allow Google to discover all your content.
- Implement pagination correctly.
- Use proper <a href> links.
- Optimize your images.
- Use server-side rendering.
- Optimize your rendered HTML to help Google pick up your content.
Let’s go through these points one by one in more detail.

Allow Google to discover all your content
Since Googlebot can crawl and render JavaScript content, there is no reason to block it from accessing any internal or external resources required for crawling and rendering.
To reiterate:
- avoid blocking important JavaScript files in your robots.txt file to allow Google to access, process, and interact with your content,
- avoid using hashes in URLs as they are a real danger of not being crawled by Googlebot,
- ensure Google can see your crucial information in the page source code, so it doesn’t need to depend on the user interaction to load the content (e.g., clicking a button.)
Also, beware of JavaScript redirects. While they are a handy solution in specific circumstances, they may set your online visibility back in several ways. Instead, it’s always better to use server-side 301 redirects.
Implement pagination correctly
Many popular websites use pagination or infinite scrolling to fragment large amounts of content.
Unfortunately, it’s very common that these websites only allow Googlebot to see the first part of paginated content as the rest is buried down on the next pages of pagination or within endless scrolls. In this case, as Google doesn’t scroll, it might not discover large amounts of valuable URLs.
Many websites use pagination that depends on a user action – a click. Instead, you should implement pagination using a proper <a href> link.
Use proper <a href> links
As you know, Googlebot not only doesn’t scroll but also doesn’t click the buttons. That’s why, the only way to let Google see the second page of pagination or discover the links to other pages on your domain is to use proper <a href> links.
In other words, add links according to Web standards to avoid depending on user actions.
An important note: having links hidden under link rel=”next” doesn’t help either. Google announced in March 2019 that they no longer use this markup.
Optimize your images
If images are an important part of your brand (e.g., presenting products on an eCommerce website) that you want to get discovered and indexed, you should optimize them for the sake of search engines.
Add your images according to the Web standards:
- link your images using the ‘src’ HTML tag, and
- consider taking advantage of browser-level image native lazy loading.
For further reading on the topic, read Marcin Gorczyca’s ultimate guide to image SEO.
Use server-side rendering
Server-side rendering allows both Googlebot and users to get a fully rendered HTML version of your website from your server.
The major SEO benefit of having your content available on the server is that it is easier and faster for bots to process it. Consequently, server-side rendering may improve the process of analyzing and indexing your pages.
What’s more, server-side rendering is also a recommended solution for presenting JavaScript content to Google.
Optimize your rendered HTML to help Google pick up your content
Take a look at the page source and the DOM (Document Object Model) and pay particular attention to your:
- crucial content,
- canonical tags,
- structured data,
- important tags like meta robots or hreflang tags, and
- internal linking.
It happens that JavaScript doesn’t change much visually, and you wouldn’t notice that it’s even there. However, it can change your metadata under the hood, which can potentially lead to serious issues.
Here’s what you can do now: Still unsure of dropping us a line? Read how JavaScript SEO services can help you improve your website.NEXT STEPS
JavaScript FAQ ‒ other JavaScript SEO questions
As we wind down here, you probably have a few questions.
And that’s great!
I put together the most common questions readers have asked me about JavaScript SEO over the years, including questions about PWAs, reducing JavaScript’s impact on web performance, serving Googlebot a pre-rendered version of your website, and more!

Can Googlebot click buttons on a website or scroll?
It’s crucial to remember that Googlebot (or the Google Web Rendering Service, to be more precise) doesn’t click any buttons, nor does it scroll the page.
The official Google documentation backs up my claim.
You must remember that if you fetch the content from a server only after a user clicks on a button, Google will not be able to see that content.
Can I reduce JavaScript’s impact on my web performance?
Yes. For instance, JavaScript code can be minified and compressed to reduce the necessary bandwidth usage; you can also use techniques like tree shaking or splitting code into chunks to only serve the necessary code at the moment when it’s necessary.
Other techniques like web workers and caching can also help boost your website performance.
Talk to your developers and ensure they adhere to the best practices Google and the web community recommended.
As Google is getting more technologically advanced, will JavaScript SEO go away?
No, JavaScript SEO isn’t going away anytime soon. If anything, it will get even more technical as new frameworks and technologies are introduced, and the web stack grows.
To quote John Mueller from Google:
[…] I don’t see JavaScript SEO dying. Because there is just so many things that you can do wrong, and it takes a lot of experience to be able to debug and find out and improve things […] You really have to know how JavaScript works, and when something goes wrong, that’s really not gonna be trivial to find. And new frameworks, like new elements in Chrome, all of these things, they kind of come together.
Nowadays, JavaScript is used by over 98.3% of all websites. If you want to outperform your competitors, you need JavaScript SEO today and in the future.
Is PWA SEO different from JavaScript SEO?
Generally, a Progressive Web Application (PWA) is a type of a JavaScript website, so all recommendations that apply to JavaScript websites should apply to PWAs.
However, there is one important fact that you should consider: Google Web Rendering Service has Service Workers disabled.
It has strong implications:
- If your website fails when a browser has Web Workers disabled, it will fail in Google rendering and ranking systems.
- If you fetch an important part of your website with Web Workers, that part will not be visible to Google.
What does mobile-first indexing mean for my JavaScript website?
The general trend is still that the desktop versions of many websites are SEO-friendly, but their mobile versions follow bad JavaScript SEO practices.
In the mobile-first indexing world, Google’s indexing system is based on the mobile version of a website. So, if you have a desktop website optimized for SEO and your mobile version has JavaScript SEO issues, you have a problem.
Things to watch for:
- Can Google render it perfectly? Use the URL Inspection Tool with User-Agent = Googlebot Smartphone.
- Can Google see your menu?
- Can Google see content hidden under tabs and “tap to see more” buttons?
- Can Google see links to the second page of pagination? (For the answer, read my article about popular websites that may fail in mobile-first indexing.)
In the past, it was enough to audit just the desktop version of a website, but that’s no longer the case.
Now, when Google is done rolling out the mobile-first indexing, Google uses the mobile version of a website for ranking purposes.
Can I detect Googlebot by the user agent string and serve it as a pre-rendered version of my website?
Yes, if you see that Google cannot deal with your client-side rendered website properly, you can serve Googlebot a pre-rendered version.
However, serving crawlers a pre-rendered version of your website, commonly known as dynamic rendering, it’s not recommended by Google as a long-term solution. On the contrary, it’s considered only a workaround for serving JavaScript-generated content.
Wrapping up
As we’ve reached the end of the article, I want to take a moment and address a problem that could affect even the best SEOs.
Sometimes when you encounter an SEO problem, your first instinct might be that it’s related to JavaScript.
And that might be very often true because JavaScript impacts your website’s indexing pipeline and web performance.
What it means for you is JavaScript SEO is extremely important to unlock your website’s full potential and grow its profitability.
However, as JavaScript-heavy pages may negatively influence your website’s index coverage, getting to the core of your SEO-related problems may be even more challenging.
That’s why it’s important to remember that JavaScript SEO is done on top of traditional SEO, and it’s impossible to succeed in the former without taking care of the latter.

Apply the principles of SEO well, and be very careful before you start blaming JavaScript.
Remember that quickly diagnosing the problem’s source will save you time and resources. Contact us with your concerns, and we’ll thoroughly analyze your pages to prepare a detailed action plan and address any of your SEO issues.

Did you like this article?
Why not share it:
Recommended posts





All you need to know about

