
Performance is currently one of the most important aspects of website optimization that SEO specialists focus on. Almost eight years ago, Google officially stated that site speed is used in web search ranking, at least for most pages. When discussing website performance and site speed, I would like to go one step further and take a look at Googlebot’s budget. In my experience, only a few of my clients (including SEOs from their teams!) take it under consideration, or maybe not as often as they should. The crawl budget is probably one of the most underrated aspects which have an indirect influence on the latest SERPs positions.
Introduction
Google’s mission as a company is to organize and structure the world’s information on the internet. Naturally, the number of pages and the general size of data is significant, according to WorldWideWebSize.com, which created the statistical method to follow the number of already-indexed pages in the main search engines – 4.5 billion indexed web pages (as of February 7, 2018). Please bear in mind that Google crawls the same webpages several dozen times per day in many cases. Thus, the general number of pages crawled per day is much higher than we would probably expect.
Nevertheless, the current speed of internet growth and the rise of valuable content are the main reasons why Google, the biggest leader of technology development, cannot handle crawling all of the sources at a sufficient rate. That is why search engine companies have implemented a “crawling budget” for all algorithms crawling the world wide web. Because of that, Google has patented many crawling techniques, such as Scheduler for search engine crawler and Method of and system for crawling a web resource. The basics are public, so all of us can delve into the mechanics of Googlebot.
How Google measures the crawling budget

Basically, Googlebot takes two aspects under consideration while setting up a crawling budget for a given website – crawl rate limit and crawl demand.
Crawl Rate Limit
Based on current server performance, Googlebot adjusts the number of requests sent to the server and the number of crawled pages. This is the so-called “fetching rate.” In other words, if the website takes too long to respond to a given number of requests, then the crawling intensity is going to decrease. This technique is really crucial for big websites, which are temporarily overloaded with user traffic. According to the main principle that Google “is designed to be a good citizen of the web”, the whole algorithm has to have a small impact on the user experience, meaning it should not slow the crawled servers/webpages and cause a degradation of the UX.
Crawl Demand
The second basic factor influencing the crawling budget for a given webpage is demand. Users are looking for valuable content. So, if a given website responds to user requests, then it should be crawled quite often by the bot to maintain its freshness in the index. The popularity of a given domain among users determines the crawling budget. Addresses that are clicked in the result pages quite often have to be fresh – Google wants to prevent the staleness of URL addresses in their SERPs. It sounds reasonable.
So what does the crawling budget mean?
How performance influences the Googlebot budget
Let’s look at how website performance (time to first byte – TTFB, time to last byte – TTLB, and time to full page load) influences the crawling budget. On the internet, we can find so many tools which help to test the performance of a given address. One of them is LoadImpact.
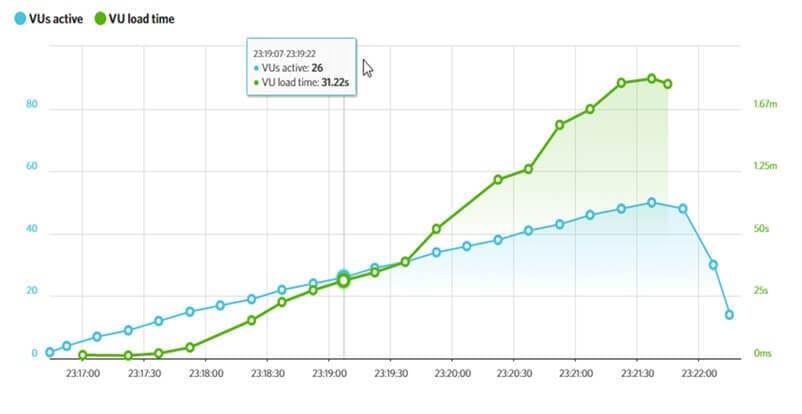
On the graph above, you can see the server has a performance issue – the green line represents the load time in seconds, the blue one represents virtual users. Thanks to this tool, we can see how our load time changes depending on the crawling load. If the LoadImpact test for your website has a similar graph, you can be sure that you are not taking full advantage of the Googlebot budget, even if your content is really valuable for users.
According to Google crawling patents, the robot budget is exactly matched to a given server’s performance. In other words, if Googlebot is intensively crawling servers and its efficiency is declining, then the bot slows down with the overall number of requests. Of course, in such a situation, the number of crawled URLs during a given period of time certainly decreases.
Case studies
I found a great example of the relationship between performance (especially time to last byte – TTLB) and crawling budget in the Google Search Console of one of my clients.
Let me briefly give you some background for context. On the website:
– there were many technical issues (performance, indexed duplicated pages, etc.),
– there was a problem with fresh content maintenance in Google index.
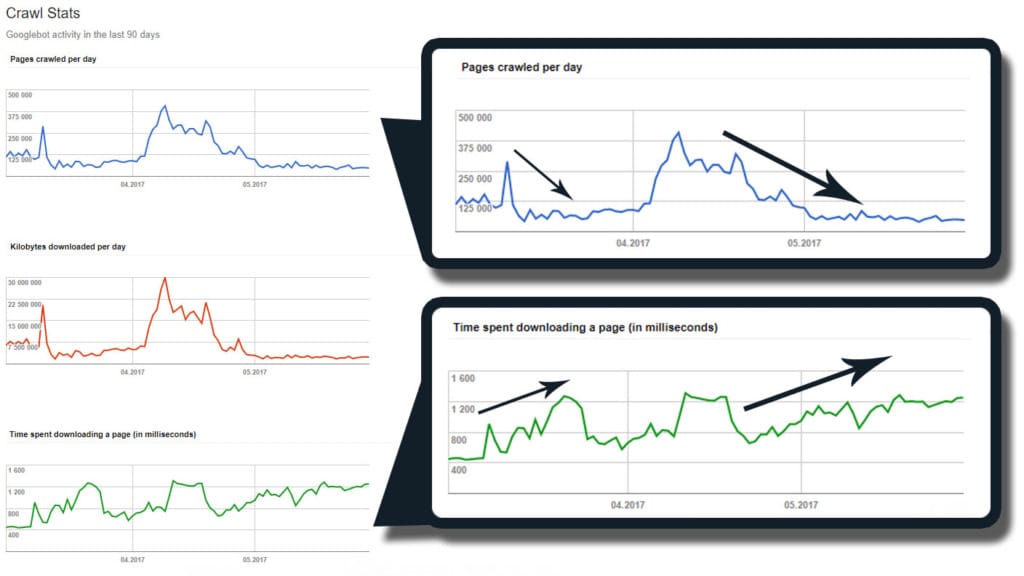
Take a look at the screenshot below:
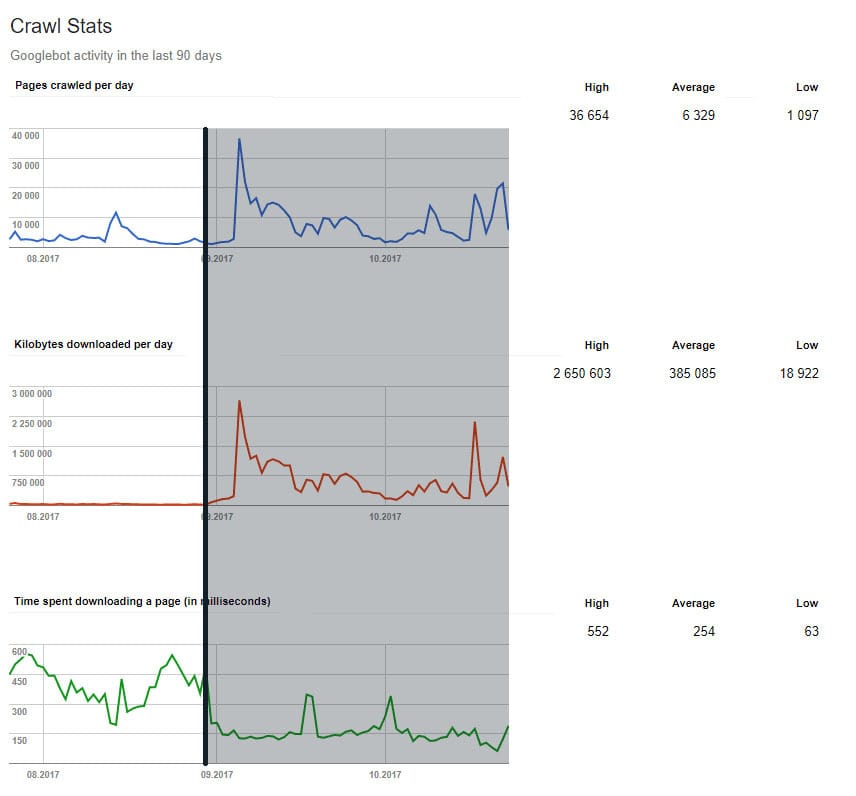
Only by changing the serving data from client-side to server-side rendering and solving a majority of technical issues were amazing results achieved (the black line shows the deployment of the production date). Then the magic began. The average time that the robots needed to download a given page decreased from ~600 to ~140 ms (and later even less!). The crawling budget increased almost five times from ~1.200 to ~5.700 URLs per day, where the highest metric was 36.654 (based on “page crawled per day” in the Google Search Console)! We can see the analogical data in the downloaded data size. I found very similar numbers in the server logs, so it was not a coincidence.
I would like to add one important point – there was no significant change in the indexation strategy, with still around 65k addresses indexed in Google.
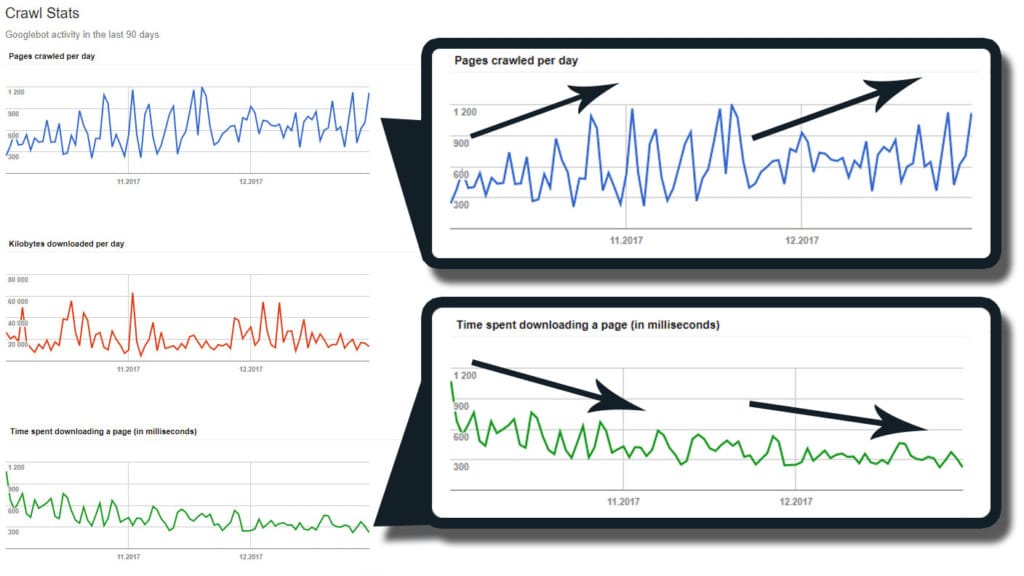
During the technical SEO analysis, I was able to identify more cases that revealed convincing evidence of page load time (TTLB from GSC tool) having an impact on the crawling rate. Some of them showed the benefits of improving performance:
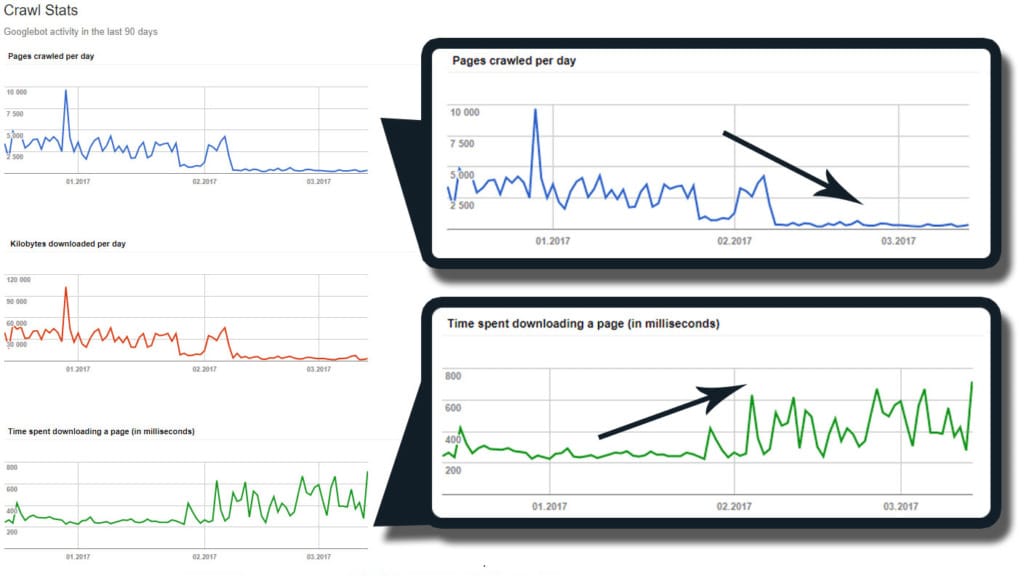
However, in some cases, we can see a different situation – as the page load time (TTLB in GSC) begins to increase, we can observe a dramatic drop in crawling efficiency:
New Relic – the panacea for servers performance diagnosis?
LoadImpact is a really useful tool to check the performance of any website. In some cases the served data might be insufficient to solve the performance issue – it gives us the diagnosis, but not the solution.
As I mentioned before, overall website performance has a tremendous influence on the crawling budget, thus an accurate and precise server issue diagnosis is crucial. You should check everything from the very beginning – first requests through time to the first and last byte sent. How much time did each action take – your framework, database, internal search engine or even caching tool? Take it one step at a time and improve everything you are able to.
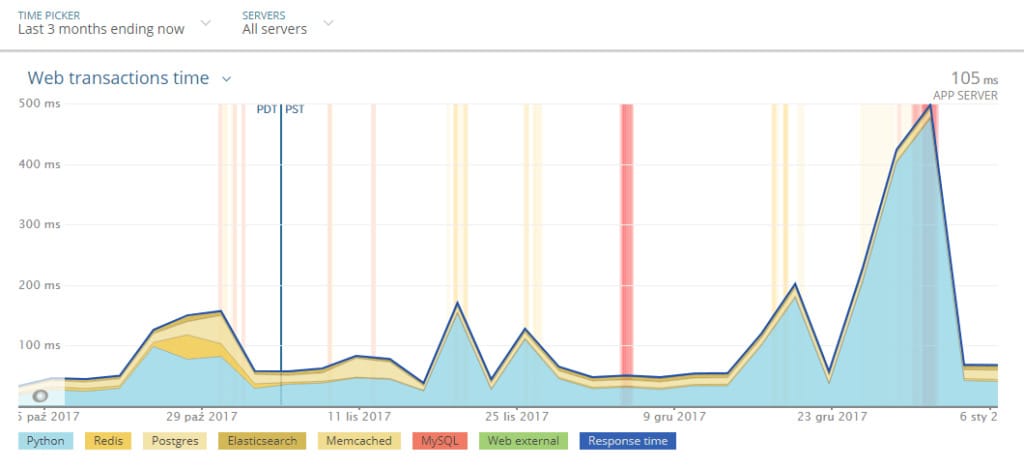
New Relic has helped me in most cases, improving server performance, especially during a cooperation with a “big cheese” where millions of pages are indexable and potentially valuable for the user and, of course, Googlebot. In those cases, on-page improvements and server-side caching did not bring the expected results. And in many cases, the reduction of TTFB/TTLB will not be reached without a diagnosis on how the server works and how much time is spent on a given action.
Conclusion
All in all, the crawling budget highly depends on your website performance – this fact is undeniable. However, it is not so clear and visible for every website. The point is that there are many other factors influencing the crawling budget – changes in the Information Architecture which increase the accessibility of valuable URLs, or the main content was changed. Please bear in mind that websites with even the best performance can have a small crawling budget – it is not the rule in every case. Furthermore, remember that the crawling budget is not a ranking factor.
If you want to increase your crawling budget, you have to basically focus on two things – the performance of your servers and crucial on-page/technical issues (e.g. soft error pages, duplicates, low-quality content, spam content, etc.). When bots find useful information and the website performance help it along, then Googlebot will crawl your website often.
If you have other observations, feel free to share them. I’m curious about your own experience regarding this issue.






