
Regular expressions are powerful and convenient tools. Thanks to them, you no longer need to search for a particular text string by hand. Paul Shapiro called regular expressions “find-and-replace on steroids.”
By using regular expressions, you can define a pattern (it can be, for example, any website URL or any e-mail address) to be found in a text.
They can be a real time-saver when working with unordered and messy data.
By reading the tutorial, you will learn:
- How to search for URLs, status codes.
- How to extract anchors from links.
- How to filter server logs to Googlebot.
- How to use a Notepad++ text editor to easily replace text fragments based on regular expressions.
Are regular expressions difficult to learn and use?
There are a lot of memes around the web about regular expressions. A lot of these memes emphasize the fact that regular expressions are difficult to write and read.
But are they really so difficult? Well, not exactly.
You can do a ton of things using only a basic knowledge of regular expressions. And more importantly, they can really improve your SEO work.



image sources: imgflip.com, dev.to, quickmeme.com
Which tools support regular expressions?
Regular expressions are widely supported by many tools around the web. The list includes:
- Popular crawlers, like Ryte (Onpage.org), DeepCrawl, and ScreamingFrog. Using regular expressions, you can do a custom extraction while crawling.
- Google Analytics (you can create custom filters using regular expressions).
- Popular editors like Notepad++, Atom, Sublime, and even Microsoft Word.
- Google Spreadsheets (you can use functions like “regexectract”).
- All major programming languages. You can extract data using regex patterns in Python, PHP, etc.
TL;DR – reference on regular expressions
Below, I’d like to present the Regular Expression Cheat Sheet.
If you don’t understand it at all now, don’t worry. I will explain everything step by step later in the tutorial. Once you learn the principles, you can go back to this cheat sheet and take full advantage of it.
| Characters | What for | Example |
|---|---|---|
| Match any digit (0-9). | d matches 0,1,2,3,4,5,6,7,8,9 – It’s the equivalent to [0-9] and [0123456789]. | |
| . | A dot (.) matches any character except a line break. | “.og” matches dog, log. |
| . | “.” means any character. How to use a dot literal? Just use “” (escape character, followed by a dot. That’s it.). | “No product description.” matches a string “No product description.” |
| s | Matches any whitespace character (a space, a newline, a tab, etc.). | “sSEO” – a whitespace followed by “SEO” string. It matches “ SEO” (space), but not (“SEO”) |
| w | Any number of “word” characters. | w matches “s”,”seo”, “1”. It’s useful in particular cases. |
| [ … ] | Matches one and only one character placed in the brackets. | [dl] matches either “d” or “l”. [dl]ogs matches both “dogs” and “logs” |
| [x-y] | Matches any character in the range from x to y. | [0-9] matches 0,1,2,3,4,5,6,7,8,9 |
| [^x] | Matches any character that is not x. |
|
| Quantifiers | ||
| + | One or more. | [0-9]+ matches any number, like 2, 301 and 1554455454545 |
| * | Zero or more. | |
| ? | |
|
|
| {n} | Exactly n times. | [0-9]{3} matches 200,301,404, but not 10 |
| {m,n} | M to n times inclusively. | .{3,4} matches any character repeated 3 to 4 times. It matches “301”, “seo”, “SEO”, “link”. But it doesn’t match “Google”. |
| {m,} | At least m times. | |
| Other important characters | ||
| ^ | Start of a string. | ^http matches “http” at “http://wikipedia.org”
But doesn’t match “http” in the following sentence: “Google doesn’t support the HTTP/2 protocol. |
| $ | End of a string. | http.+d+$
matches URLs that end with a number, e.x http://somerandomurl?id=55456 |
| () | Capture a group. | |
| Special classes – negations | ||
| D | Matches any non-digit character. | D+ matches any string that doesn’t contain digits. |
| S | Matches any non-whitespace character |
Let’s Get Ready To Rumble
Let’s start with some very basic examples. But one important note – don’t go any further without running regex-testing software.
You can use a great online tool: Regex101. It’s free of charge.
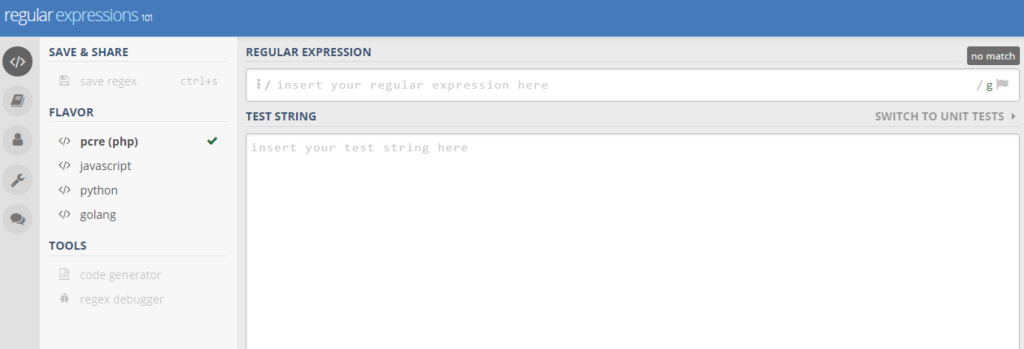
Match “cats”, “dogs” and “logs” using a single expression
Let’s say you would like to find “dogs” and “logs” in a text file. Easy enough, right? Just search for “dogs” and then “logs”.
But you don’t need to do it this way. Here is where regular expressions come in handy.
A regular expression that catches all these words is “[dl]ogs”. Explanation: the “[dl]” expression matches one of these letters: d, l.
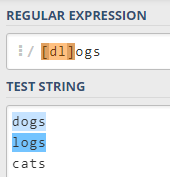
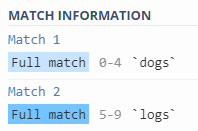
Generally speaking, “[…]” matches any single character placed inside square brackets. So, for example, “[0123456789]” matches any digit, but not a number.
The dot to rule them all
You can use . (a dot) to match any character.
“.ogs” matches “dogs” and “logs”.
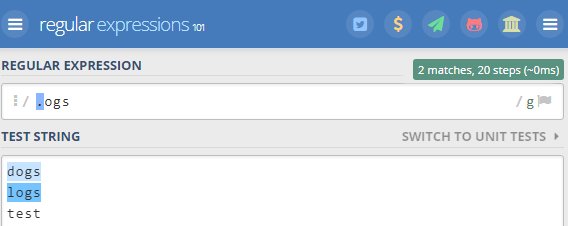
Important note: you can still use a dot as a literal. If you want to match “No links found.”, just use an escape character, followed by a dot.
So the expression would look like this: “No links found.”. That’s it.
The plus and question mark modifiers
It’s high time to introduce “+” and “?” modifiers. These are very useful because they allow for avoiding repetitions:
- “+” modifier means “at least one occurrence”
- “?” modifier means ‘“zero or one occurrence”
Let’s say you have a file with a list of URLs:
- http://somerandomurl.com
- http://somerandomurl.com?x=dfdf;y=3
- http://somerandomurl.com
- http://somerandomurl.com/products/4544554
- http://somerandomurl.com/products/45454
- http://somerandomurl.com/products/category/garden/
- http://somerandomurl.com/products/category/garden/2
and you want to match all the URLs containing numbers.
You can use the following regular expression: “Http.+[0-9]+”. This expression means: search for a “http” string followed by anything, followed by any sequence of numbers.
1. Matching only URLs containing a product number
Depending on your needs, you may want to match only URLs containing product IDs (SKU). If so, we have to improve our regular expression.
We need to match “http” followed by any number of chars, followed by /products/, and finally, a series of numbers.
Important note: we can’t just type “/products”, because “/” is a reserved character. You have to use backslash – an escape character (). So, our final expression to only catch URLs containing a product SKU would look like this:
http.+/products/[0-9]+
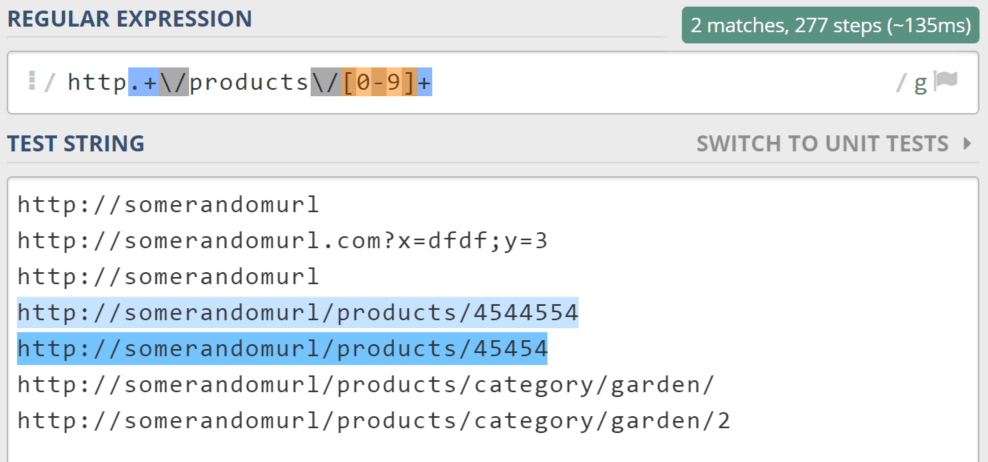
2. How to match HTTPS pages as well?
Now, let me introduce a question mark (?) modifier, which means “zero or more occurrences.”
There are some https websites around the web, so let’s match them.
All we have to do is to add “s?” to our previous example, after “http”. So the final expression would look like this:
https?.+/products/[0-9]+
How to interpret this regular expression? “Http” string followed by a non-obligatory “s”, followed by any string, followed by a string like “/products/45645”.
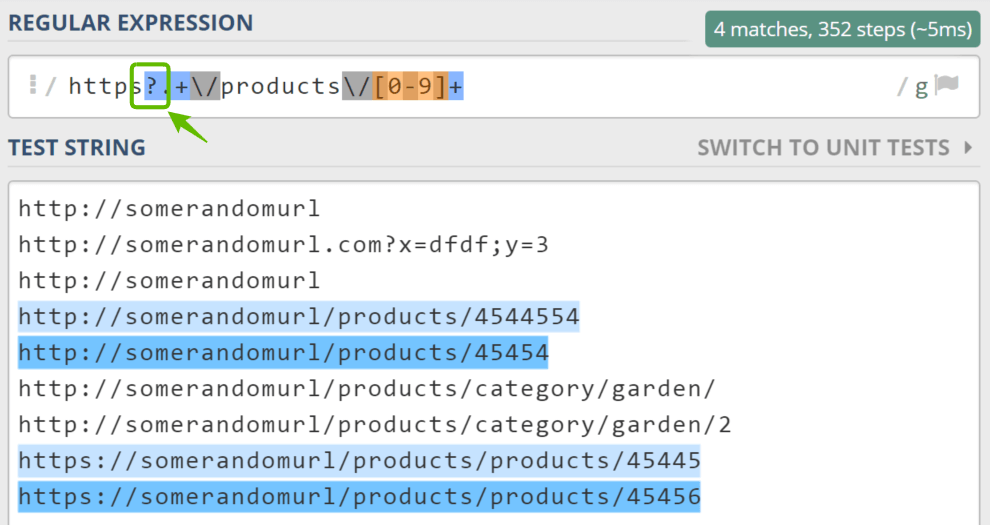
Quantifiers
[0-9] matches any single digit, like 1, 6, or 7.
What if you want to match HTTP status codes (consisting of 3 digits)? Should you write [0-9][0-9][0-9]?
Not necessarily. You can just use a {3} quantifier.
So, “[0-9]{3}” matches 200 and 301.
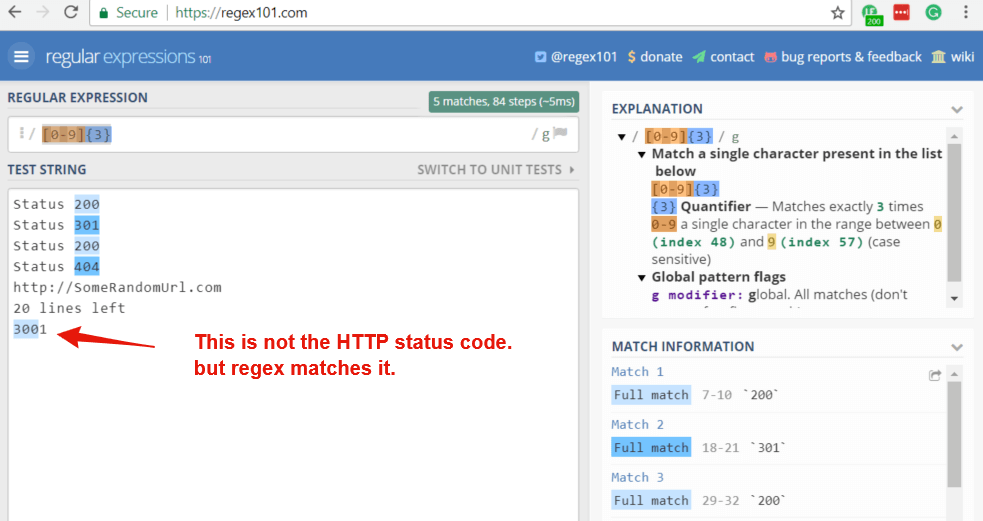
However, please note this expression also matches part of the “3001” string. It should be avoided. Below, I will show you how to avoid such pitfalls.
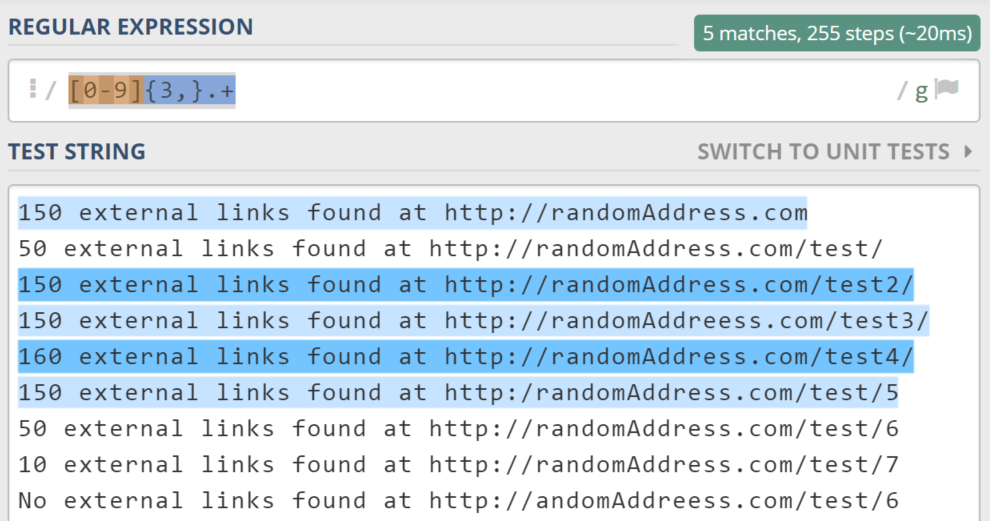
More than X occurrences
Imagine your website audit software generates reports in plain TXT instead of using more organized formats, like CSV or XLS.
150 external links found at http://SomeRandomAddress.com
50 external links found at http://SomeRandomAddress.com/test/
150 external links found at http://SomeRandomAddress.com/test2/
150 external links found at http://SomeRandomAddreess.com/test3/
150 external links found at http://SomeRandomAddress.com/test4/
150 external links found at http://SomeRandomAddress.com/test/5
No external links found at http://SomeRandomAddreess.com/test/6
What if you want to find URLs that have more than 100 external links?
Well, “100” has three digits. We have to use the {3,} quantifier:

So “[0-9]{3,}.+” does its job well. That’s it.
Capture groups
When talking about regular expressions, a capture group function is extremely useful.
Let’s say you would like to match all link anchors in the following URLs list:
Here is where a capture group feature comes in handy.
How do you use it? As usual, type a regular expression that matches the whole HTML link.
Then, wrap (using parentheses) the part you want to “catch.”
OK, let’s start building the regular expression. How would you match the entire link?
You are right, it would be something like this: “.+”
- Opening bracket (<);
- then “a href” followed by any sequence of characters (.+);
- closing bracket (>);
- any sentence of characters (that makes an anchor);
- and finally a stop.
The question arises: how do you match an anchor within this expression?
Just wrap (using parentheses) the part which consists of an anchor.
| Before | After capturing group |
.+
 |
(.+)
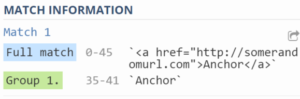 |
Character classes
You don’t need to write “[0-9]” all of the time. Instead, you can use its equivalent: “d”
There are many other character classes in the Regular Expression world that make our life easier. Earlier in the document, I mentioned the following classes:
- [a-z] matches every lowercase letter.
- w matches any “word” character (both lower and uppercase letter, a digit, as well as an underscore (_) character. It’s the equivalent of “[a-zA-Z0-9_]”.
- s matches any whitespace character. Using it, you can catch a space and a tab, as well as a newline. It’s very handy because the data around the web is usually a bit messy.
The beginning and the end of a string
Let’s say you have a messy file containing info about product availability:
- The product is not available.
- The product is available. Note: in the case the product is not available, call us.
How do you deal with such a file?
“The product is not available” is simply not enough. It makes fake matching.
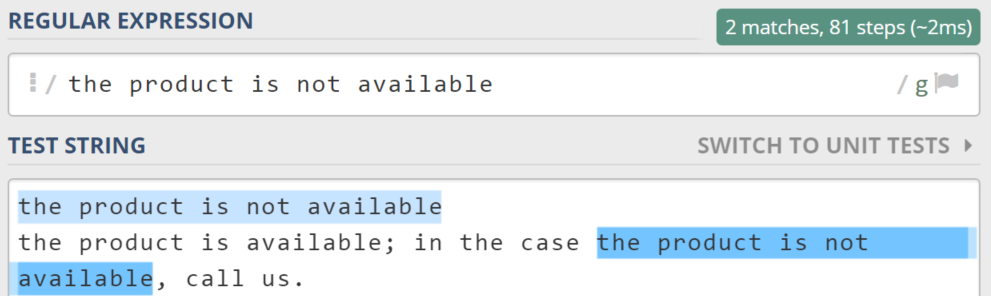
To avoid such pitfalls, you can force a regex search engine to match only the strings that start with “the product is not available”.
All you have to do is add “^” at the beginning of a regular expression.
So, the final expression would look like this: “^the product is not available”
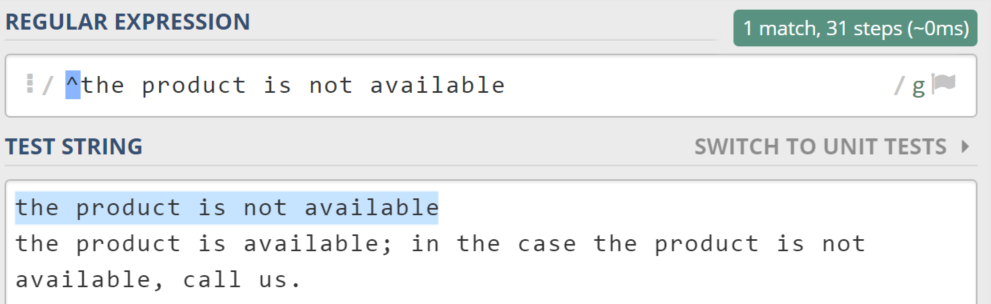
How do you match a string that ends with a particular string?
Just add the dollar sign ($) at the end of the regex.
Another extraction from a text
Let’s say you want to extract some information from the following text:
9 Ladies Dancing: 10 Lords a-Leaping: 11 Pipers Piping: 12 Drummers Drumming
The challenge here is to match “9 Ladies, 10 Lords, 11 Pipers, 12 Drummers” using a single expression. How would you do that?
The regex is simple: “d+sw+”
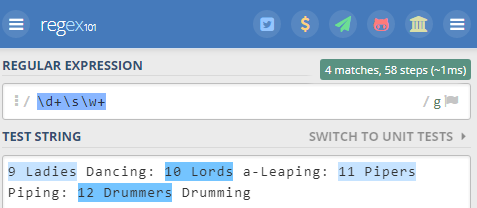
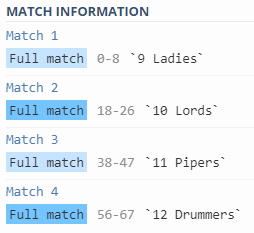
Here is how to interpret this regular expression:

Some real-world examples
1. How to filter server logs to Googlebot
This part is addressed for those SEOs who deal with server log analysis.
This scenario is so common: You have the access log of a big website for an entire month. It’s ~10gb of raw data to analyze.
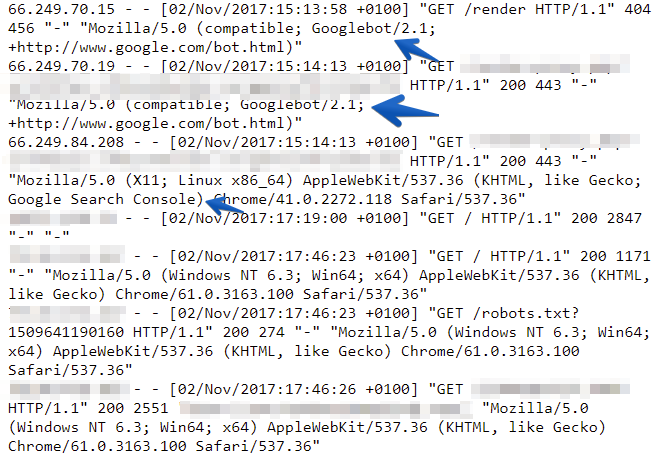
The good news is that it’s very easy to filter server logs to Googlebot. You can use a Grep tool for this task. It’s built-in most Linux systems. If you are a Windows user, you can use Grep via Cygwin, which emulates the Linux environment in Windows.
Don’t get scared! The whole process will take approximately three minutes and will definitely pay off!
- Download Cygwin from https://cygwin.com/install.html.
- Install it. There are many installation options, but it’s enough to just click “Next” all the way through.
- Open Cygwin.
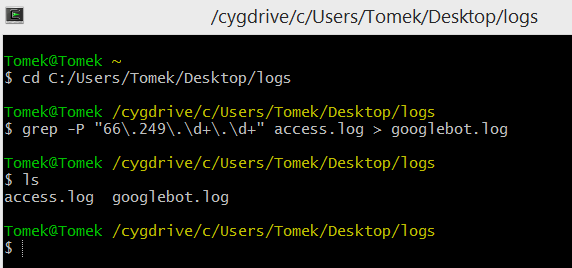
- Type a “Cd” command followed by the path where you store server logs. In my case, it’s “cd C:/Users/Tomek/Desktop/logs”.
- Type “ grep -P “66.249.d+.d+” access.log > googlebot.log”.
That’s it. Now the file is ~90% smaller than it was at the beginning 🙂
Now let me explain what is happening here.
Since Googlebot’s IP starts with “66.249”, I’ve used the following pattern: “66.249.d+.d+” (“66” followed by a dot, followed by “249”, followed by a dot, followed by some digits, followed by a dot, followed by some digits).
Grep is looping through all of the lines of an input file (access.log) and saves only those which stores information about the Googlebot (“66.249.d+.d+”) pattern to a googlebot.log file. Don’t forget about the “-P” parameter!
Note: Here, I am filtering Googlebot through its IP address range: 66.249*. If you wish, you can still filter data with User Agent. Regex would look like this: Grep -P “Googlebot” access.log > googlebot.log.
2. Using regular expressions with Notepad++
A significant number of text editors do support regular expressions. Notepad, a popular text editor, is no exception.
Let’s imagine you have a text file with a list of URLs:
http://somerandomurl.com/home-equipment/product/45455442
https://somerandomurl.com/car-equipment/product/4545222
http://somerandomurl.com/bikes/product/45442
http://somerandomurl.com/sport/product/555464
http://somerandomurl.com/swimming/product/4545541
http://somerandomurl.com/computers/product/454543
Let’s say, you want to rewrite this file to include information about a product’s category and its ID.
What regular expression matches it? Let’s test it through regex101.com.
It could be “(https?://somerandomurl.com/(.+)/product/(d+)”
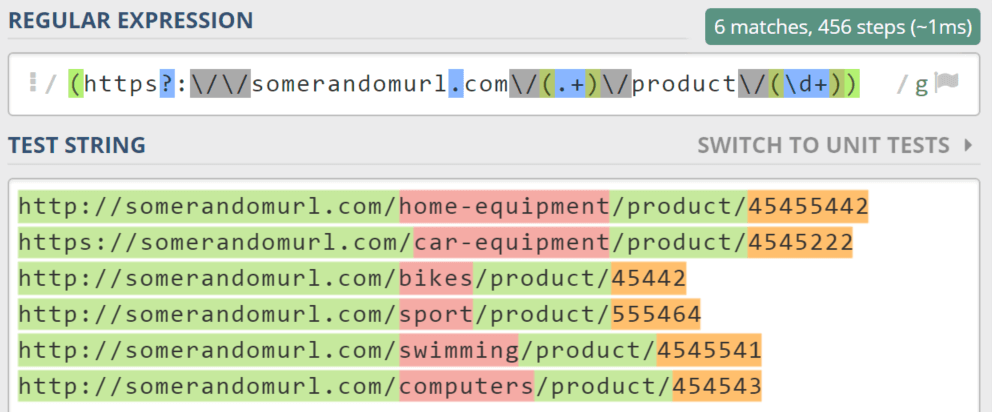
As you can see on the screenshot below, this regex does its job well:
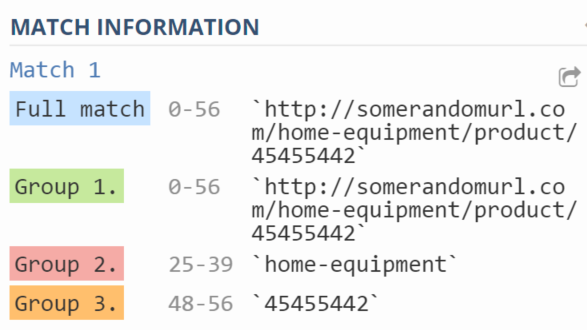
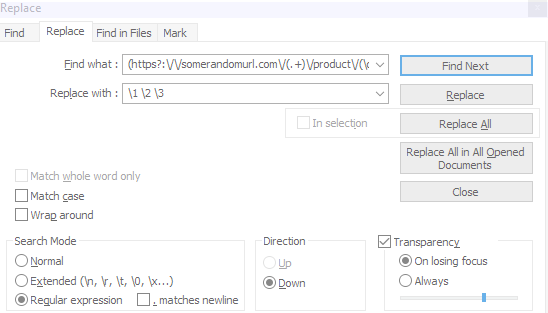
How do you easily extract these groups and use them to rewrite the file? You can use Notepad++ to do this. Click Search->Replace (or Ctrl+H), and then:
- Make sure you use the “Regular expression” search mode.
- Type the regex in the “Find what” field.
- Write “1 2 3” in the “Replace with” field (this formula means: “find the desired pattern, replace it with the first matched group, followed by a space, followed by the second matched group, followed by a space, and finally, followed by the third group).
- Click “replace all”.
3. Matching parts of URLs
The results are as expected:

4. Regular expressions for matching a website structure
Let’s say you are consulting a website that provides a huge listing of professionals. The list includes professionals of any occupation – SEOs, lawyers, etc, from all over the world.
And you want to check in Google Analytics how often a professional’s profiles are visited by the website’s users. The website structure is depicted in the drawing below:
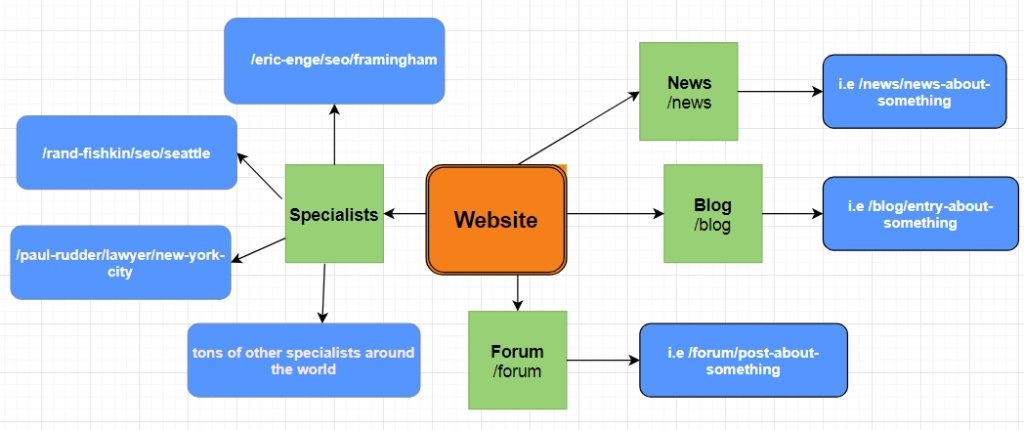
But wait, there is a problem: the URL structure of the specialists is complicated. And it seems regular expressions are the only way to match it.
Here is a sample of URLs:
- /rand-fishkin/seo/usa-seattle
- /eric-enge/seo/usa-boston
- /paul-rudder/lawyer/usa-new-york-city
- /andrew-x/seo-sem/canada-toronto
Example URLs that shouldn’t be matched (these belong to other categories, like “blog”, “forum”, or “listings”):
- /seo/usa-new-york
- /blog/entry-about-something
- /forum/post-about-google-search-console
Don’t worry. It should easily be done with regular expressions.
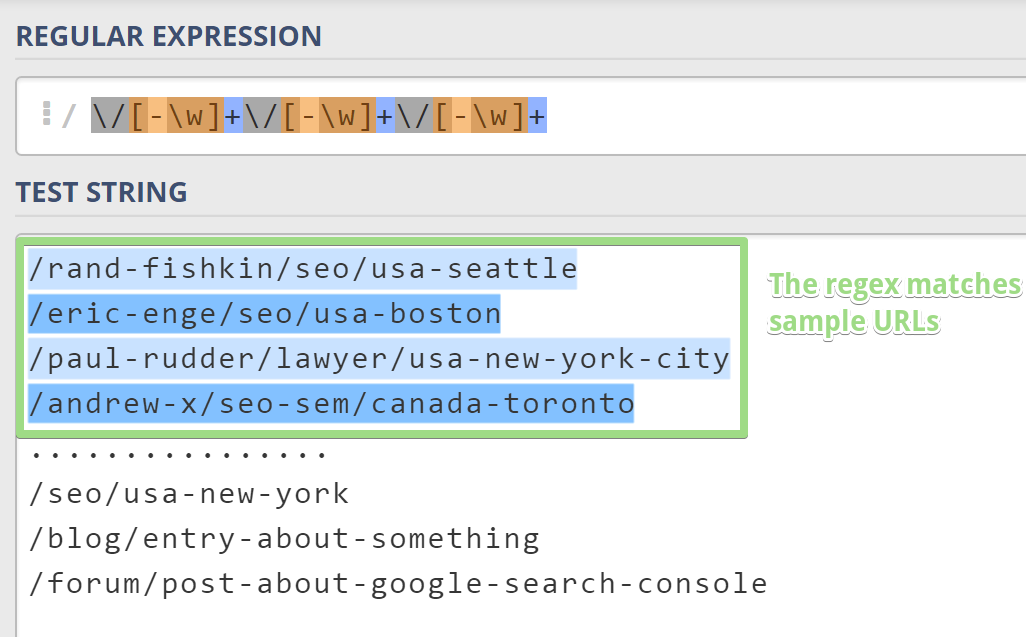
Let’s discuss the regular expression:
- “/” matches a slash literal.
- [-w]+ matches any positive number of “word” characters or a minus sign. So, this part can match “eric-enge”, but also supports additional hyphens, so it supports “eric-enge-stonetemple” or “jean-claude-van-damme”.
Maybe you’ve noticed, but the whole expression is made by only two blocks: a slash literal and “[-w]+”. Let’s call these blocks “A” and “B” accordingly. What does the whole expression look like?
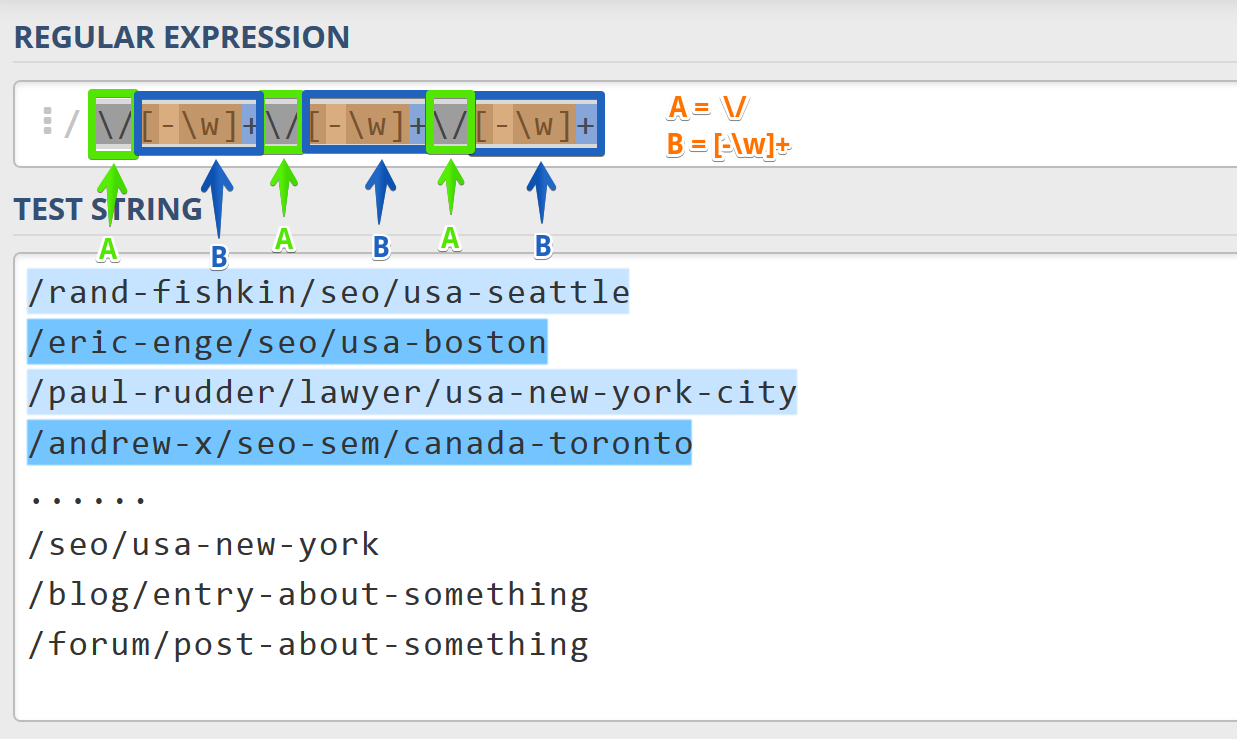
Ok, we’ve got the final expression. It’s time to type it in Google Analytics:
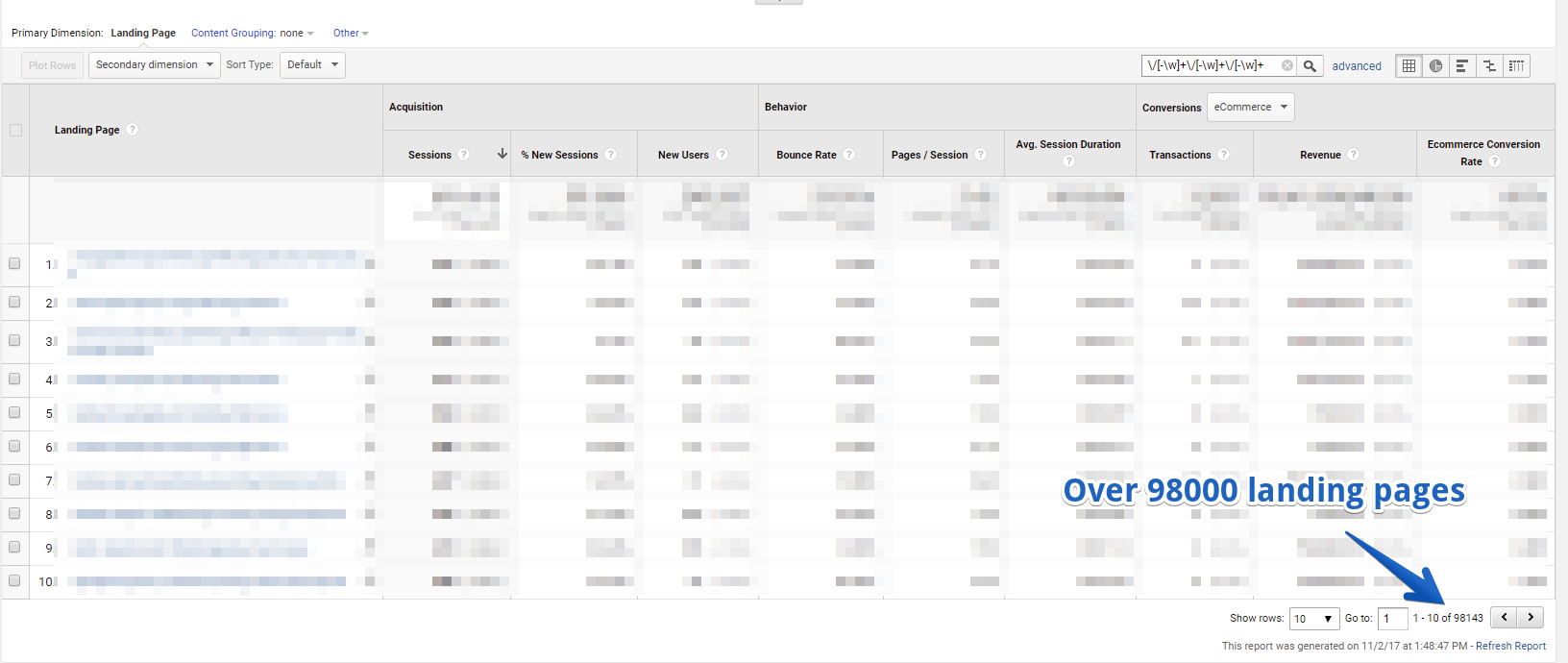
Voilà! Almost 100,000 specialists’ profiles were found in Google Analytics. By the way, I’m sorry for blurring the Google Analytics view, but the example used is real and I don’t want to reveal its Google Analytics data.
Making regular expressions less error-prone
1. Boundaries
Let’s talk about “b” (“word boundary”). It’s a great feature that prevents fake matching. For instance, you want to match the HTTP status code (it consists of 3 digits), so you write “[0-9]{3}” or d{3}. But there is a problem: this expression also catches 4-digit numbers.
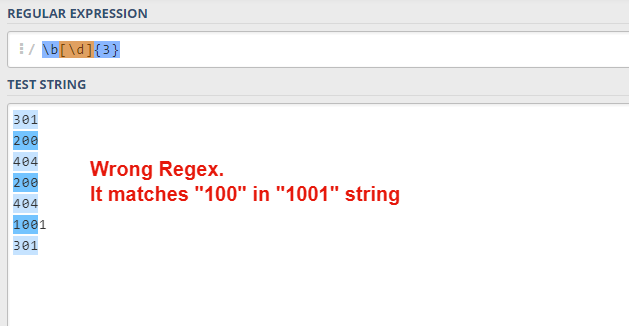
In order to avoid such pitfalls, you can use word boundaries. So, the final expression would look like this: “b[d]{3}b”.
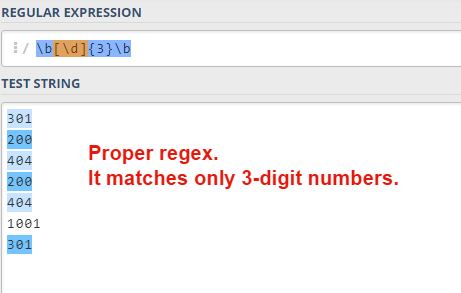
That’s it!
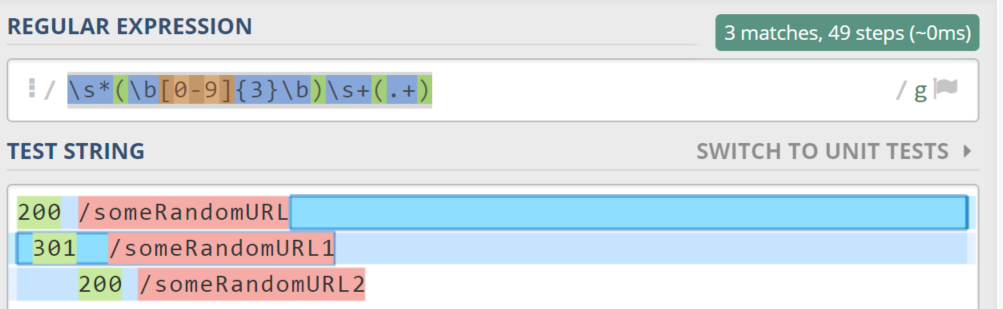
2. Whitespaces
There is a huge number of messy documents around the web. They often contain things like whitespaces, before and after a desirable string.
Let’s say you have a quite messy file containing the following lines:
200 /someRandomURL
301 /someRandomURL1
200 /someRandom URL2
How do you match it?
It’s a good option to use the following regex:
“s*(b[0-9]{3}b)s+(.+)”
- Any number of whitespaces.
- Three digits (the first matched group).
- Single whitespace.
- Any string.

Further reading
My goal was to teach you the principles of regular expressions. I hope it worked out!
Now it’s time to practice the knowledge you gained:
1. TreeHouse – RegEx practice/tutorial – one.ly/regex
2. I strongly recommend going through the interactive tutorial at https://regexone.com/
The very first tasks are pretty straightforward. Then, there are some additional tasks, like parsing and extracting data from URLs that will allow you to go deeper into the regular expression world.
3. Regular expressions for Google Analytics
4. A Marketer’s Guide To Using Regular Expressions In SEO







